Tank and Drv are SuperFetch plugins to emulate streaming and use the Drive REST API with Apps Script. SuperFetch is a proxy for UrlFetchApp with additional features – see SuperFetch – a proxy enhancement to Apps Script UrlFetch for how it works and what it does.
This is another in my series on SuperFetch plugins.
Tank, Streaming and Drv
You can see more about Pseudo streaming for Apps Script (it doesn’t support real streaming natively), at SuperFetch Tank Plugin: Streaming for Apps Script
This article will cover how to copy very large files using Tank to stream and Drv to upload and download partial content. The Apps Script Drive services have a limit on the size of files you can write, and very large memory usage can potentially cause Apps Script to fall over mysteriously – like this – ‘The JavaScript runtime exited unexpectedly”
UrlFetch also has a maximum payload size of 50mb (it used to be 10mb), but in reality I’ve found it can drop bytes (the number of bytes in the payload received doesn’t match that reported in the response header) on payloads of over about 20mb.
You can also use SuperFetch Tank to stream between Drive and Google Cloud Storage (with more platforms in future releases). SuperFetch has a Cloud storage plugin (gcs) which I’ll cover in another article.
How Tank and Drv work together
Drv creates a filler function which grabs the content of an input file a chunk at a time and adds them to an input tank. When the input tank is full, it is emptied into to the output tank.
When the output tanks detects it is full, it uses and emptier function that Drv creates to write a chunk to the output file. This is repeated until the input file is exhausted and the output tank is empty.
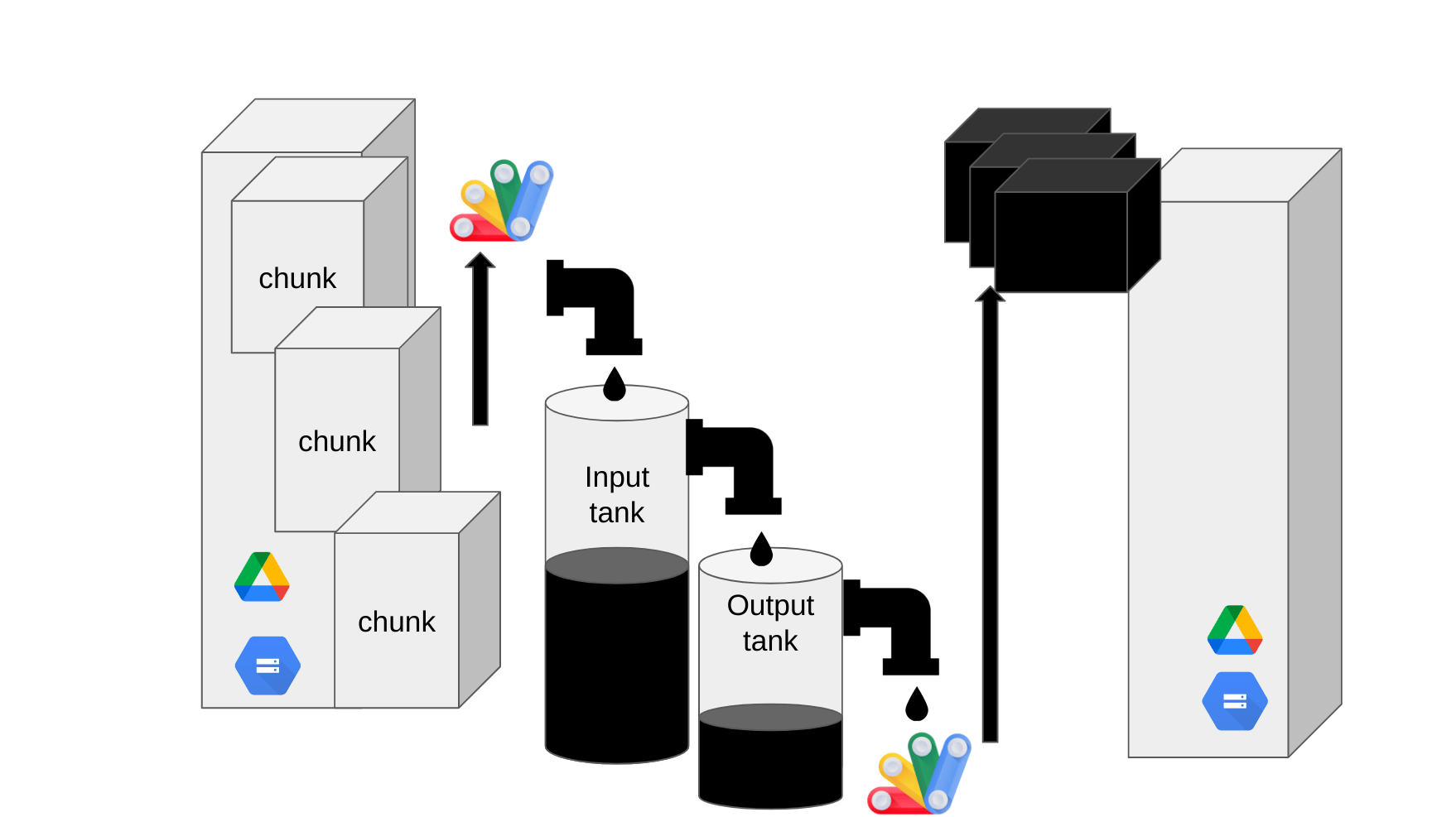
The tank capacities, and the size of chunks that will be written or read are each independent of each other and can each be tweaked to get the best overall result.
Getting started with Drv and Tank
Let’s say we have a video file to make a copy of with Apps Script. It’s way over the Apps Script DriveApp and UrlFetch size limit, so we’re going to want to stream it.
Script Preparation
You’ll need the bmSuperFetch library and if you want to run some tests, the bmUnitTest library – details at the end of the article.
Import the Tank & Drv plugin, and ensure you have the drive api enabled and the proper scopes. This is described in detail in SuperFetch plugin: Google Drive client for Apps Script – Part 1 if you need some info on how to do that.
We’ll create a SuperFetch instance.
We’ll also need a Drv instance. For this example, we won’t bother with caching
Usage
If you’re already familiar with Drv, you’ll know there are many ways to get a file by path/ref/id/name. For this example, we’ll define the input file by id, and the folder into which to put the result like this.
Create read and writestreams
A stream holds information about the input and output files, and the create() method will automatically make its tank and filler and emptier functions
The writeStream will need the size, and contentType of the input file (which can be picked up from the bigstream) as well as a name. It knows which folder to put it in via tankPath created earlier.
Pipe one to the other
Now we just need to pipe the tank of the readstream to the pipe of the writestream.
And that’s it!
Checking it worked
The readstream and writestream contain a number of useful properties, the main ones of interest being
- readStream.init – the result of the initializing the download
- writeStream.upload – the result of finaliing the upload
In both cases, they hold a superFetch response – which looks like this
And the data property will hold metadata about the input and output files – like this
So you can check that all worked by comparing the checksum
Or, you could even fetch the metadata of the new output file and check it
Logging
As described in SuperFetch Tank Plugin: Streaming for Apps Script Tanks have a number of events that we can associate an action with. It’s possible to setup these events for tanks created automatically too.
In this example, I’ll push the tank readings to log arrays each time the level changed, or the pipe operation is complete so we can visualize the data movement during the pipe operation.
Visualizing tank readings
Since we’re in Apps Script here, we as may well write the logging to a sheet. I’m going to use the bmPreFiddler library for this, as it makes sheet manipulation a bit less laborious. ID details at end of post.
Here’s how the tanks contents and levels looked throughout the pipe operation with default maxPost size and tank capacities of 20mb.
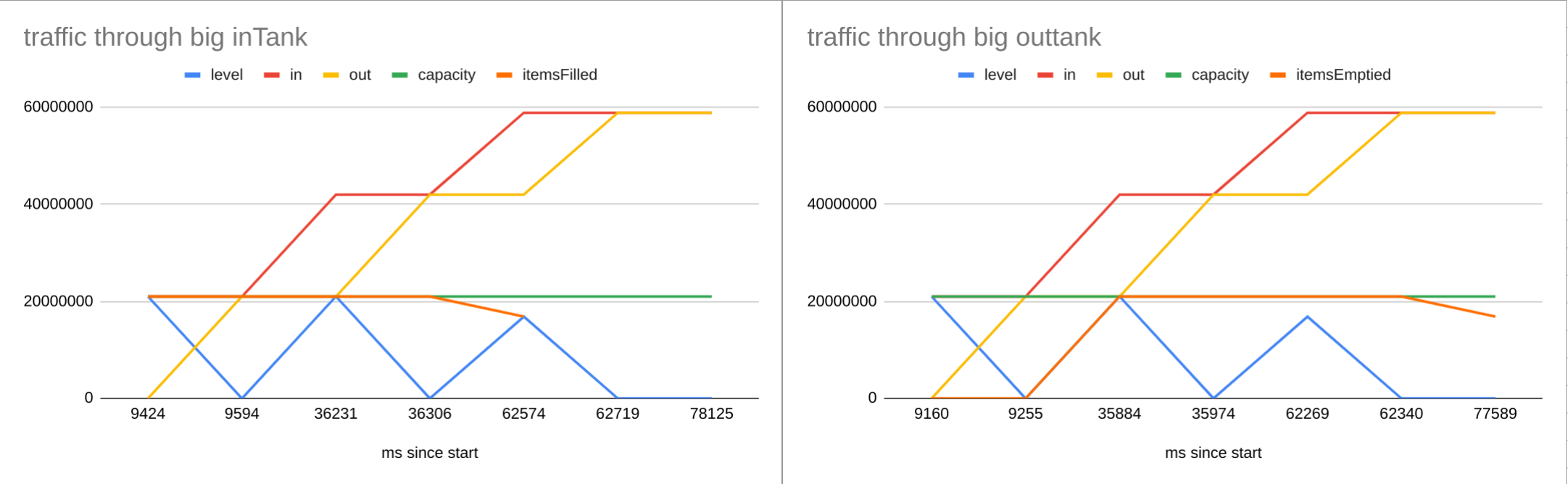
Capacity
I recommend you leave the tank capacities as they are, matching the maxPost size for Drv. However they can be set as a parameter to the stream.create({capacity: 20000}) method if you want to play around. Note that any value you supply will be rounded up the nearest 256k (a requirement of the Drive API).
You can change the maxPost default when you create your drive instance – for example
new Drv ({ superFetch, maxPost: 1024 * 1024})
This will become the default capacity for all tanks if you do that.
What if the file doesn’t need to stream
Drv has download and upload methods. The regular upload method automatically supports uploading in chunks and in most cases they’ll do fine.
However, if you use streaming, and the tanks are bigger than the file size, everything will still work just fine.
Here’s a visualization of a 1 mb file passing through 20mb tanks. As you can see it all happens without any tanks filling.
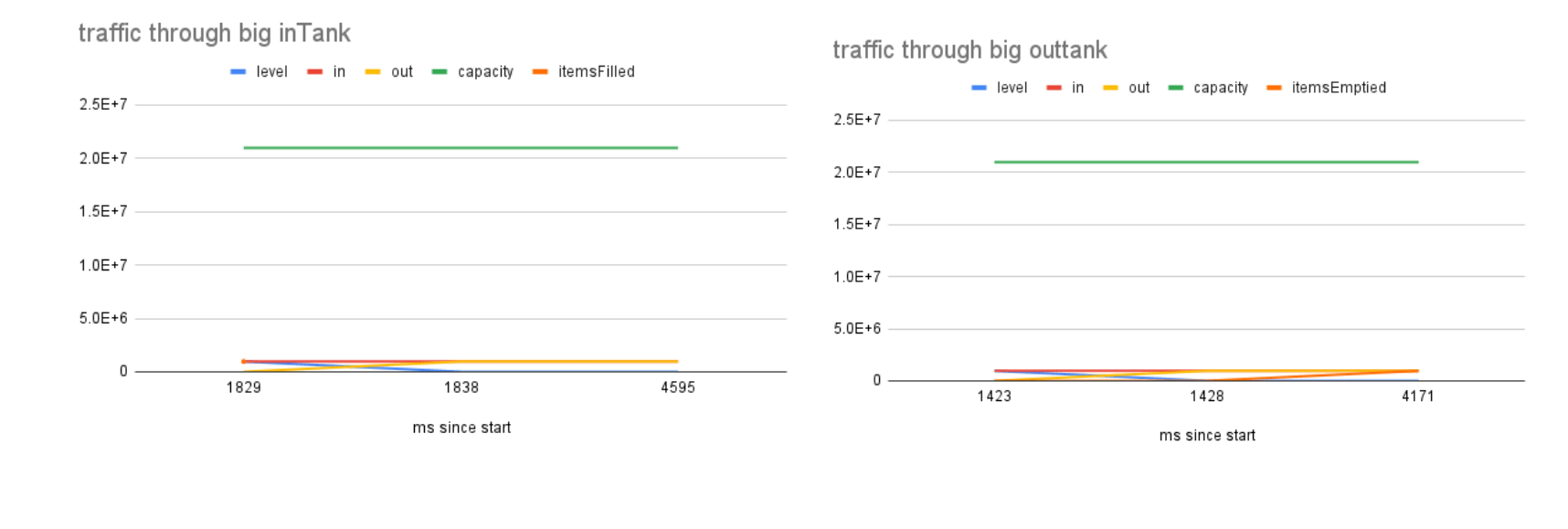
Transform tanks
Although we’ll typically be piping just the input to the output tank, you can pipe as many tanks together as you want. These intermediate tanks are called transform tanks, and take a transformer function. You can use transformer tanks to modify data as it passes through the pipes.
I’ll cover these in another article. However, if you use transformer tanks, you may want to change the capacity from the default if your transforms need it (for example if you are calling some kind of API with a paging limit to do the transformation)
Unit testing
I’ll use Simple but powerful Apps Script Unit Test library to demonstrate calls and responses. It should be straightforward to see how this works and the responses to expect from calls. This shows how to test the functions mentioned in this article.
Next
Next I’ll be showing how to pipe between different services – eg gcs and drv, and how to use transform tanks. Over time, many SuperFetch plugins will support piping between them.
Links
bmSuperFetch: 1B2scq2fYEcfoGyt9aXxUdoUPuLy-qbUC2_8lboUEdnNlzpGGWldoVYg2
bmUnitTester: 1zOlHMOpO89vqLPe5XpC-wzA9r5yaBkWt_qFjKqFNsIZtNJ-iUjBYDt-x
bmPreFiddler (13JUFGY18RHfjjuKmIRRfvmGlCYrEkEtN6uUm-iLUcxOUFRJD-WBX-tkR)
Related

Convert any file with Apps Script

Caching, property stores and pre-caching
State management across CardService, HtmlService and Server side Add-ons

SuperFetch Plugin: Cloud Manager Secrets and Apps Script
SuperFetch caching: How does it work?

SuperFetch plugins: Tank events and appending
SuperFetch Plugins: Apps Script streaming with Tank and Drive

SuperFetch Tank Plugin: Streaming for Apps Script

SuperFetch plugin – Google Drive client for Apps Script – Part 1

SuperFetch – Twitter plugin for Apps Script – Get Follows, Mutes and blocks
SuperFetch plugin – Twitter client for Apps Script – Counts

OAuth2 and Twitter API – App only flow for Apps Script
SuperFetch plugin – Twitter client for Apps Script – Search and Get

Apps Script Oauth2 library Goa: tips, tricks and hacks
Apps Script Oauth2 – a Goa Library refresher

SuperFetch plugin – Firebase client for Apps Script
SuperFetch plugin – iam – how to authenticate to Cloud Run from Apps Script
SuperFetch – a proxy enhancement to Apps Script UrlFetch
Apps script caching with compression and enhanced size limitations
