Because we’re doing server side actions here, we can use a service account. That’s simpler than playing around with Node Oauth2 if you are using a pedefined Drive belonging to you. However there are a couple of extra wrinkles as a result of using a service account with your own Drive folder to host the data being shared between Apps Script and Node. Actually, you can of course share between Node and Node too, but in any case, you’ll still need to get accesss to a Drive.
Creating the service account
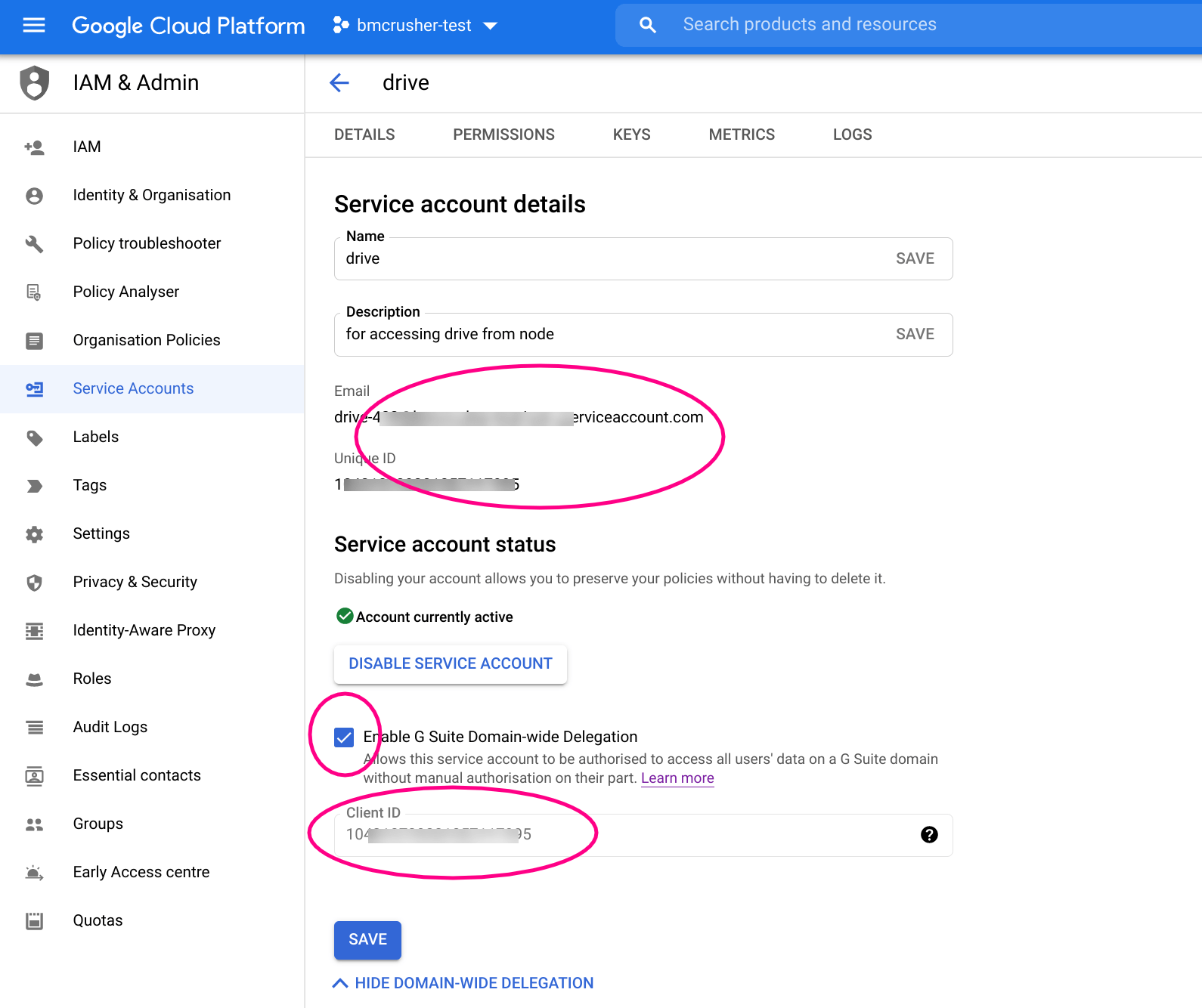
In the Cloud Console, enable the Drive API, create a service account key and pay particular attention to the items marked here. You’ll need them later.
You can then download the json file for that account and put it somewhere private in your Node project. Remember – Don’t commit it to github.
Impersonation
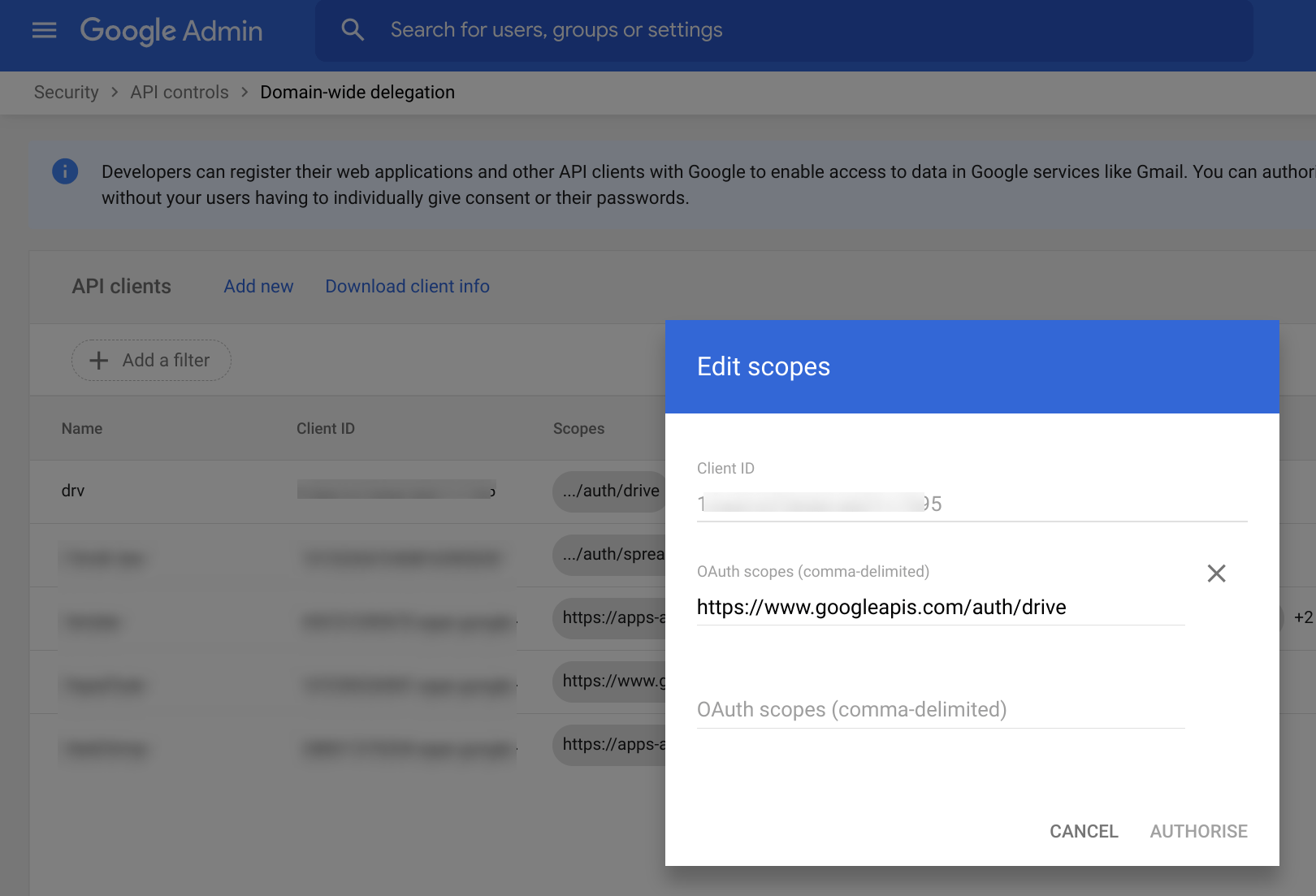
The first step in enabling impersonation is to enable G Suite delegation for that service account – done above when the service account is created. Next, we need to allow that that service account to have access to the scopes we’ll allow it to access. That’s in admin.google.com. You need to get the clientID from the service account, add it, and allow it the drive scope.
That’s the set up over, and we should be good to go. I’ll walk you through a utility module to interact with the Drive API from node
Writing your own Drive access module
If you are here because you are using the bmcrusher-node module, then you’re done. However if you are writing your own module, here are some tips.
Let’s assume your wrapper module will call this as pass over the JSON file and email address to impersonate. The first step is to get an auth object you can use with the Drive client.
/** * get an auth object * @param {object} options * @param {object} options.credentials the content of the service accoutn JSON file * @param {string} options.subject the email address of the account to impersonate * @returns {GoogleAuth} */ const getAuth = async ({ credentials, subject }) => { // use JWT uth for serviec account with a subject for impersonation const auth = new google.auth.JWT({ email: credentials.client_email, key: credentials.private_key, scopes: ["https://www.googleapis.com/auth/drive"], subject, }); return auth.authorize().then(() => auth); };
get an auth object
Client
You’ll need an instatiated client, with the auth built in. This will call the auth function from above. This will be the primary interface into the methods in this Drive access client. It’s important to use v3 (not v2) as there were a number of changes to property names between the two versions – and the code following will all be for v3.
/** * get an authenticated client for Drive * @param {object} options * @param {object} options.credentials the content of the service accoutn JSON file * @param {string} options.subject the email address of the account to impersonate * @returns {Drive} a client */ const getClient = ({ credentials, subject }) => getAuth({ credentials, subject }).then((auth) => google.drive({ version: "v3", auth, }) );
instatiated Drive client
Creating a file
The bmcrusher-node module writes base64 compressed versions of the data, so we only need to support text here, but it’s straightforward to extend this to other mimetypes if you need to. Rather nicely, the Drive API supports streaming, so we’ll be reading and writing all content using streams – this is the same approach I use with the Cloud Storage version. If you want to write the file at the top level, simply omit the parents argument, otherwise provide the id(s) of the file’s parent(s). I recommend you avoid having multiple parents for the same file. It’s just a pain.
/** * create a drive file * @param {object} options createfile options * @param {string} options.name the file name * @param {string} [options.mimeType = "text/plain"] the mimetype * @param {Drive} options.client the authenticated client * @param {[string]} options.parents the id's of the parents (usually onlt 1) * @returns {File} response */ const createFile = ({ name, mimeType = "text/plain", client, content, parents, }) => { const requestBody = { name, mimeType, }; if (parents) { if (!Array.isArray(parents)) parents = [parents]; requestBody.parents = parents; } // we'll do this as a stream const options = { requestBody, }; if (content) { const s = new Readable(); s.push(content); s.push(null);
options.media = { mimeType, body: s, }; }
return client.files.create(options); };
create a file
Creating a folder
You may need to create a folder to put your file into. We can simply use the createFile method with a folder mimtype and no content. If this is a subfolder, the parent parameter should be the id of the parent folder of the folder being created. We defined the FOLDER mimeType earlier.
We can use the LIST method with a query to get a collection of files that match that query. If you’re expecting a bunch of files then you’ll have to handle paging. My use case expects only 1, but handles a few. If the file is in a subfolder, then provide its parent id(s) in the same way as before.
/** * get files that match a given name * @param {object} options options * @param {string} options.name the file name * @param {Drive} options.client the authenticated client * @param {[string]} options.parents the id's of the parents (usually onlt 1) * @returns {[File]} files */ const getFilesByName = ({ parents, client, name }) => { const options = { q: `name='${name}' and trashed = false`, orderBy: "modifiedTime desc", }; if (parents) options.q = ` and '${parents[0]}' in parents`; return client.files.list(options).then((res) => { const files = res && res.data && res.data.files; // it's always possible there are multiple versions, even though they get cleaned up return files; }); };
get a files by name
Getting a file content by id
Once you’ve used get file by name to get the Ids, you can get the file content. This uses a stream to get the file content, so we’ll need a way to convert the stream into a string to return it – see later.
/** * get file content for a given id * @param {object} options options * @param {string} options.fileId the file id * @param {Drive} options.client the authenticated client * @returns {object} the {content, res, fileId} */ const getFile = ({ fileId, client }) => { return client.files .get( { alt: "media", fileId, }, { responseType: "stream", } ) .then((res) => streamToString({ readStream: res.data }).then((content) => ({ content, res, fileId, })) ); };
get file content
Converting a stream to a string
A stream is a chunk of bytes that have to be later concatenated and converted. Here’s a function to do that.
/** * get a string from a stream * @param {object} options options * @param {Readable} options.readStream the input stream * @returns {string} the content */ const streamToString = ({ readStream }) => { return new Promise((resolve, reject) => { const chunks = []; readStream.on("data", (chunk) => chunks.push(Buffer.from(chunk))); readStream.on("end", () => resolve(Buffer.concat(chunks).toString("utf-8")) ); readStream.on("error", (err) => { // this is ok as it may not exist if (err.code !== 404) console.log("failed stream to string", err); reject(err); }); }); };
stream to string
Removing a file
This is by id
/** * remove a file for a given id * @param {object} options options * @param {string} options.fileId the file id * @param {Drive} options.client the authenticated client * @returns {Response} the ressponse */ const removeFile = ({ fileId, client }) => { return client.files.delete({ fileId, }); };
removing a file
Folder iteration
That was the easy part, but let’s say the file you want find is in a folder structure with a path like /crusher/store/data/mydata.txt. We’ll need to iterate through that folder structure to find the id of the parent folder of mydata.txt. If we’re creating a file like that we may also want to create the folders as we go if they don’t already exist. There are a number of solutions to this, but asynchronous recursion is not a lot of fun. However an asynchronous iterator makes it a littler simpler.
for await of
Using an iterator makes the overall structure very simple and clean. The final result is the id of the last folder on the path. In this case, we also want to create any folders that are missing from the path as we loop through
/** * get the id of a folder at the end of a path /a/b/c returns the drive file for c * @param {object} options options * @param {string} options.path the path * @param {Drive} options.client the authenticated client * @returns {File} the parent folder at the end of the path */
It looks like a bit of a handful, but the pattern is pretty straightford. The job of the next() method is to return one of the two results above to be dealt with in the for loop. The source data is the folder path, split into an array of its components. Each time next() is called we slice off another component and find that using the previous list folder result as the parents of the query – and keep going till we run out of folders – optionally creating new ones as we go.
Usage
Here’s some example using all those methods
(async () => { // get a client const client = await getClient({ prefix: "/crusher/store", credentials: getDriveCreds(), subject: "bruce@mcpher.com", });
// write something const content = "some data";
// top level const res = await createFile({ client, content: "some stuff at top level", name: "toplevel.txt", }); // get it back const { content: topContent, fileId } = await getFile({ client, fileId: res.data.id, }); console.log(topContent, fileId);
// delete it await removeFile({ client, fileId });
// get a handle to some folder, and create it if necessary const { id } = await getFolder({ client, path: "/some/folder" });
// create a dile in that folder const { data } = await createFile({ client, content: "some stuff at sub level", name: "sub.txt", parents: [id], });
bruce mcpherson is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. Based on a work at http://www.mcpher.com. Permissions beyond the scope of this license may be available at code use guidelines