Some information on performance of each of the back ends in Database abstraction with google apps script
The library reference is
Mj61W-201_t_zC9fJg1IzYiz3TLx7pV4j
Comparing linearity
In Relative performance I covered performance of scriptDB versus Parse versus DataStore. Overall, Parse came out best on all counts between the 3. Since that time I’ve added a few more backends, and also done more extensive performance tests, as in Comparing all back ends performance. Driver MongoLab is now the best player, beating even in memory (where all the querying is done of an in memory dataset in Google Apps Script). One of the things to look at is performance linearity – as you operate on more data, is there a point at which certain backends become unviable. Lets look at the applying the test cases across increasing amounts of data – starting with 30 and going to about 800 – not much but I need to do lots of tests while staying within within the GAS quotas. These initial tests delete all the current records, write them again , then do a whole bunch of queries, saves, counts, removes and updates on the loaded data – and of course check the results are as expected. The main objective is to exercise how this might be used in real life. I make the point again that we are testing my implementation of these backends (which is what matters if you are using this library), not necessarily the capabilities of the database provider itself. The library source is open so feel free to help improve it, or even contribute your own driver for your favorite database (see How to write a driver) I’m dogged by quota exceeded problems doing these kind of bulk tests. In fact I can barely do DataStore since I quickly exhaust my daily operation quota – so it more or less disqualifies itself on that grounds alone. I even busted the 50,000 Urlfetch operations a day so had to run these over a number of days. I have excluded scriptDb, orchestrate and fusion since their performance in the basic tests are way out of line with these others. Of course there are always run time fluctuations in both the apps script environment and the cloud provider’s database. I’ve turned results caching completely off for all these tests.
Here’s the first set of results
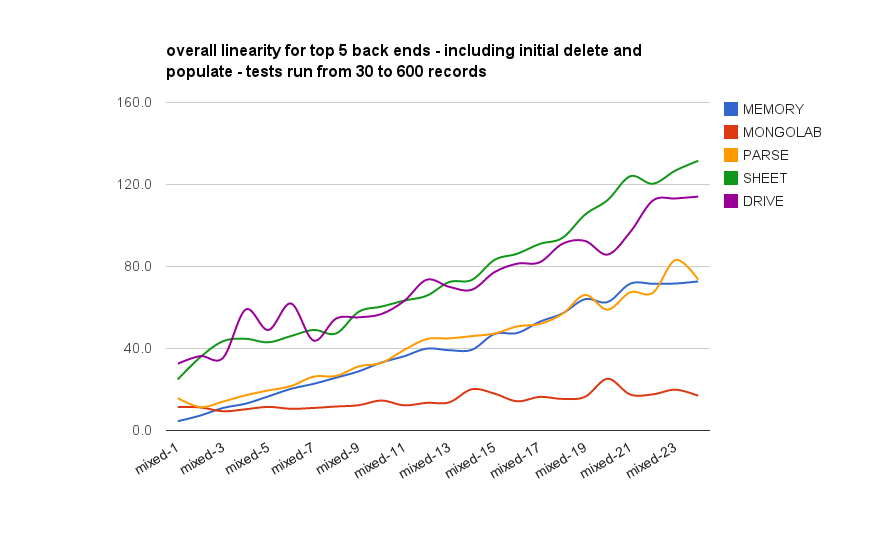 The x axis shows an increasing number of records, and the y how long to run all the tests, including deleting and initially loading. What we’re looking for is good linearity, with increasing time being mainly to do with the internal gas processing and checking as the database size increases, rather than being caused by the size of the database itself. What I’m expecting to see is Parse and MongoLab performing well, memory fairly linearly, and Sheets and Drive with poor linearity. Both Sheet and Drive use the Memory driver behind the scenes since they have no underlying db capability, so they will themselves be affected by the linearity of Memory – so if we extract the memory measurement, we’ll roughly see the linearity of Sheet and Drive themselves.
The x axis shows an increasing number of records, and the y how long to run all the tests, including deleting and initially loading. What we’re looking for is good linearity, with increasing time being mainly to do with the internal gas processing and checking as the database size increases, rather than being caused by the size of the database itself. What I’m expecting to see is Parse and MongoLab performing well, memory fairly linearly, and Sheets and Drive with poor linearity. Both Sheet and Drive use the Memory driver behind the scenes since they have no underlying db capability, so they will themselves be affected by the linearity of Memory – so if we extract the memory measurement, we’ll roughly see the linearity of Sheet and Drive themselves.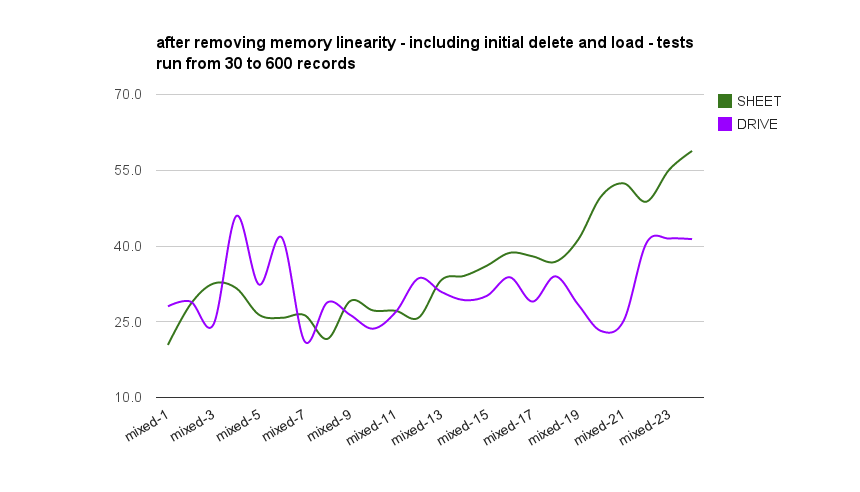
Removing the initial loads and deletes
This doesn’t really reflect how this would be used though. so if we start timing after the initial load and delete, we should get a better real world performance measure. Ideally we’d like to see modest increases only across the different phases caused more by the queries are returning incrementally more data, and the increasing success validation complexity, rather than the back end itself. 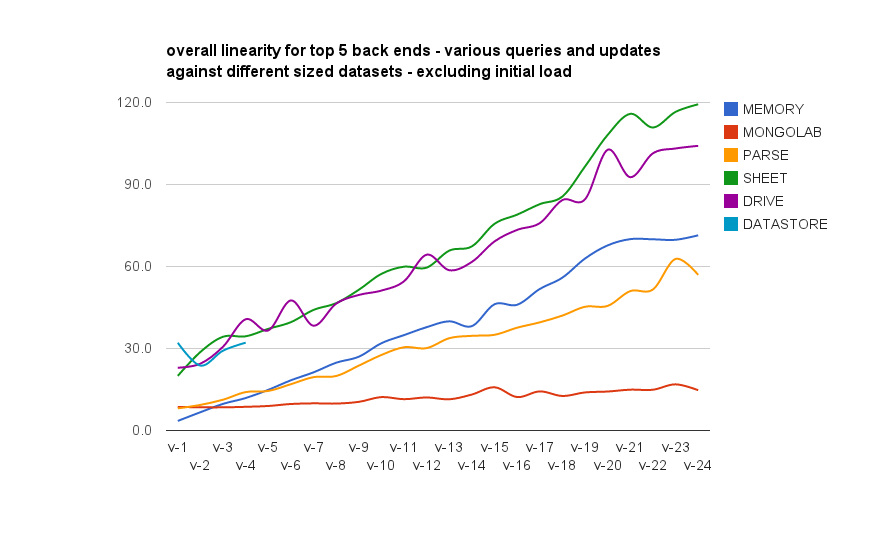
and here’s sheets and drive without the memory effect
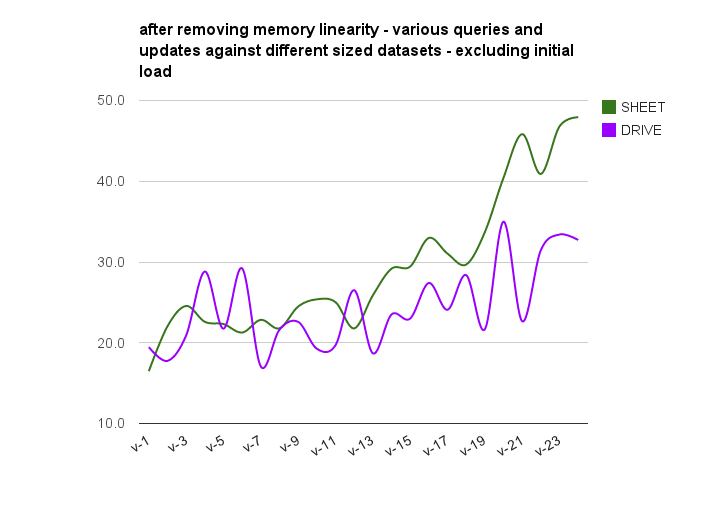
Summary
Using sheets or drive are simplest, and for small datasets (< 300 rows), even with the heavy querying, deleting and updating going on in these soak tests hold their own. However, on every measure, I’m going to go for Driver MongoLab as a standalone GAS replacement for ScriptDB, but watch out for the pricing plans. Right now you can have a sandbox with 500mb for free to get started, but it doesn’t claim any reliability like the paid plans, and it may be throttled back at some point. I’ve noticed this with Parse.com where it started off really fast, but now the free plan seems to hit throttling problems more often than before. Anyway, with this kind of abstraction, changing database later is a simple matter of getting a different handler. See more like this in Database abstraction with google apps script , Driver MongoLab and Comparing all back ends performance