Sometimes you need to generate some fake data for a spreadsheet. In this post I’ll cover a few utilities in 2 separate libraries that can help with this.
Faker
This is a node module to create fake names, addresses and many other things. I won’t reproduce the methods, but you can find the documentation here. This apps script library (bmFaker) is simply a wrapper for faker. All the methods mentioned are available.
It’s a very large library and comprehensive so I’m keeping it standalone, so you should only load it if you need it for creating test data.
Usage
const { faker } = bmFaker
Some examples of usage follow.
RandomThings
In addition to generating test data from faker, you may also want to generate some random stuff, in particular, data that follows a particular statistical distribution. This library has a number of useful utilities to help with that. Some of them are adapted from d3 – see all about d3 on Github ,and others are unique to this library.
Usage
const { RandomThings } = bmRandomThings
Methods
RandomThings.distributions
This namespace can generate an array of random data of a given distribution.
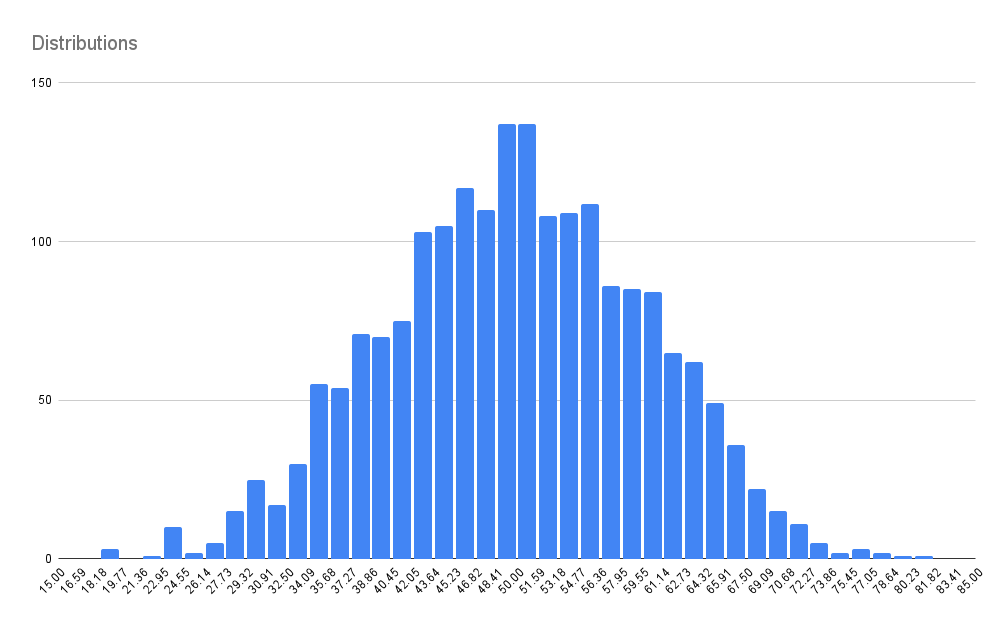
RandomThings.distributions.normal ({ mean = 0, sd = 1, length = 1 })
Create normal distribution of length, with an expected value of mean, and a standard deviation of sd
example
const normal = RandomThings.distributions.normal({ mean,: 50, sd: 10, length: 2000 })
distribution
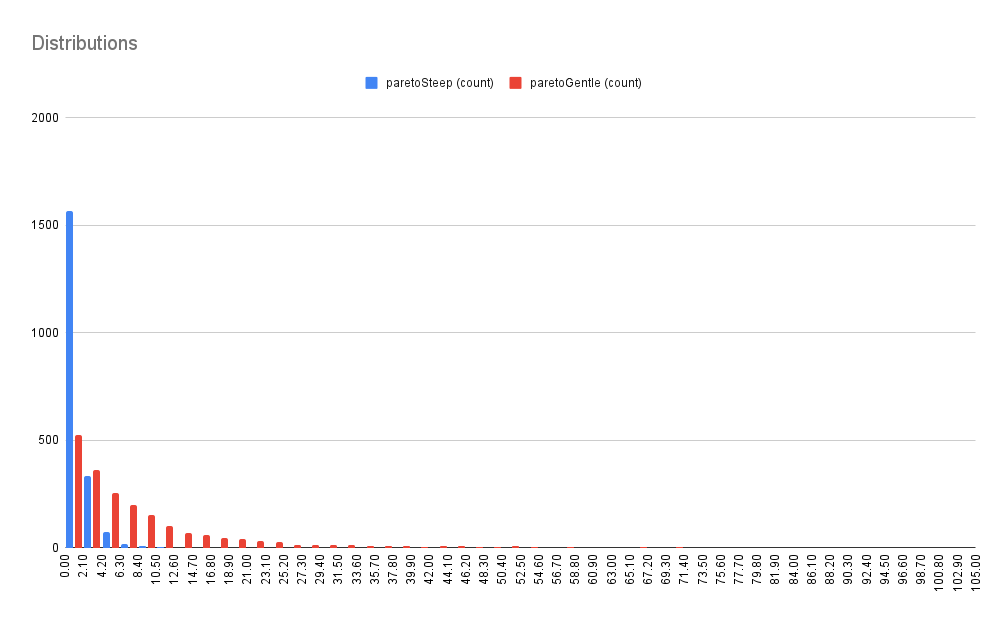
RandomThings.distributions.pareto ({ alpha = 1, length = 1 })
Create pareto style distribution of length elements with a steepness of alpha. This will normally be used with the RandomThings.closure.scale() to limit the values within a given range. (see below for more on .scale())
example
const paretoSteep = RandomThings.distributions.pareto({ alpha: 25, length: 2000 })
const paretoGentle = RandomThings.distributions.pareto({ alpha: 5, length: 2000 })
const paretoScale = RandomThings.closure.scale({ max: 100, values: paretoGentle.concat(paretoSteep) })
const paretoSteepScaled = paretoSteep.map(paretoScale) const paretoGentleScaled = paretoGentle.map(paretoScale)
distribution
The result will be 2 sets of random pareto shaped values that look like this
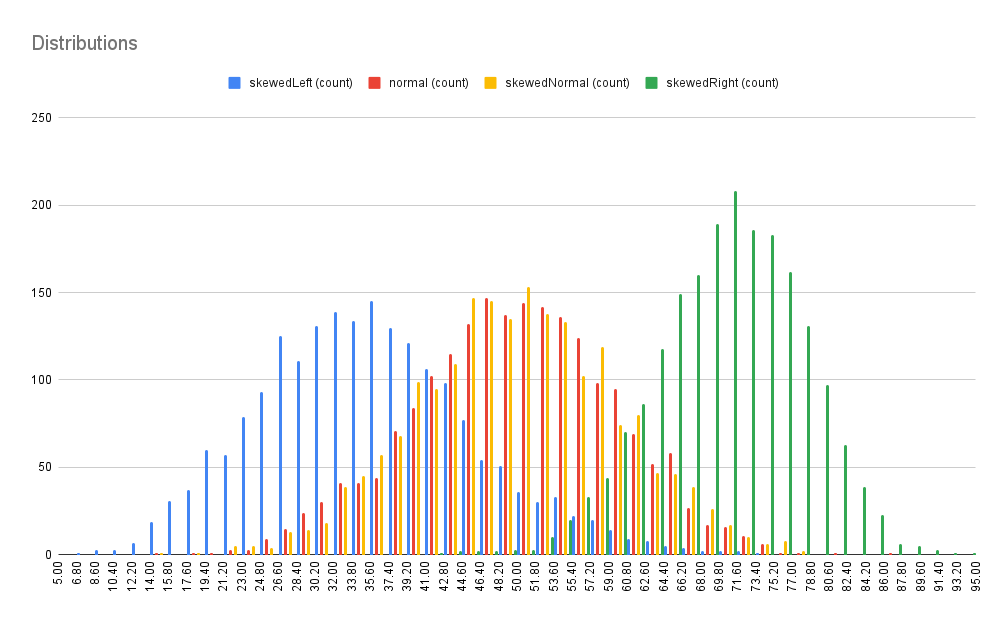
RandomThings.distributions.skewed ({ min = 0, max = 1, skew = 1, length = 1 })
This is a distribution with a skew to bias either left or right.
example
This example will plot 4 distributions 1 skewed left, 1 normal, 1 skewed normal and 1 skewed right. A skew of 1 will produce a distribution skewed to the middlw, >1 skewed to the left and < 1 to the right.
constskewedLeft = RandomThings.distributions.skewed({ min: 0, max: 100, skew: 1.5, length: 2000 })
constskewedRight = RandomThings.distributions.skewed({ min: 0, max: 100, skew: 0.5, length: 2000 })
constskewedNormal = RandomThings.distributions.skewed({ min: 0, max: 100, skew: 1.0, length: 2000 })
const normal = RandomThings.distributions.normal({ mean,: 50, sd: 10, length: 2000 })
distribution
RandomThings.selection
This name space is about selecting from lists
RandomThings.selection.member (arr)
Takes an array and picks a random member. Although used internally for picking characters, this can be used to pick random elements from arrays of anything.
example
RandomThings.selection.member(['bob', 'ted', 'alice']))
result
bob
RandomThings.string
This name space generates various random strings.
RandomThings.string.digest (…args)
Takes any amount of any kind of arguments of any type and return a SHA1 digest in websafe base64.
example
RandomThings.string.digest(100, {name: 'something', id:20}, 'fred')
result
MRMatELvwVtIBHH1wlc4kWGxZl8=
RandomThings.string.make ({ length = 32, charTypes = null, unique =false} = {})
Creates a string of length from various char types.
If unique is true, then the current time will be used as part of the string
The charTypes argument should look like this. You can choose to include or exclude as required. Lower case, upper case and numeric characters are the default setting.
{
upper: Boolean,
lower: Boolean,
space: Boolean,
accents: Boolean,
specials: Boolean,
custom: RegExp
}
example 1
RandomThings.string.make()
result
1SAn6Jx8SOknMOUgwEzhNn4mYsUxtIyw
example 2
RandomThings.string.make({length: 10})
result
I2YpsNyrPf
example 3
RandomThings.string.make({length: 10, charTypes:{upper: true}})
result
IQMDBVJXJV
example 4
RandomThings.string.make({charTypes:{lower: true, custom: /[F-S#\-_]/}})
result
S#cxgIJPiiIfcmQduRrJSnKep-OsG-a_
example 5
RandomThings.string.make({length: 10, charTypes:{custom: /[a-f0-9]/}})
result
8f3652ac79
example 6
RandomThings.string.make({length: 40, charTypes:{space: true, accents: true, numbers: true , upper: true, lower: true, custom: /[S-Z]/}}))
result
SzxxÈ8cYzòÓÃÚ3NÏKÈôÏôSZòz4ÊÝÛajXvQîÓöézÙ
example 7
RandomThings.string.make({length: 24, charTypes:{specials: true}})
result
'+):~?}`)-``*!+ %]^*#\~\
example 8
RandomThings.string.make({length: 24, charTypes:{specials: true}})
result
'+):~?}`)-``*!+ %]^*#\~\
Unique
The unique option includes the current time in the mix, which will reduce the chance of collissions. That means that ids created around the same time will have part of the string similar or the same, but with additional random characters to disambigurate, and strings created at any other millisecond are guaranteed to be unique. The timestamp is encoded using the charset selected. If you want to aim for absolute collission avoidance perhaps a UID would be a better choice, but this approach should be good enough for most cases.
example 9
2 unique’s created at a similar time using just the lower case character set
RandomThings.string.make( {unique: true, length: 20, charTypes:{lower: true}})
RandomThings.string.make( {unique: true, length: 20, charTypes:{lower: true}})
results
sgmqisxbgcebjaicbefa
xqxufaxbgcebjaicbefb
example 10
RandomThings.string.digest(RandomThings.string.make( {unique: true, length:100}))
result
JRzEE-IdoRxWEOjcQ26izjziz-k=
RandomThings.number
This name space generates various random numbers.
RandomThings.number.between (min, max)
Returns a whole number between min and max
example
RandomThings.string.between(100, 120)
result
105
RandomThings.number.digits ({length =5}= {})
Returns a random number with length digits
example
RandomThings.string.digits({length: 8})
result
95141551
RandomThings.closure
This name space generates various closure functions
RandomThings.closure.scale ({ min = 0, max = 1, values = [] } = {})
Returns a function that can be used to scale values between min and max.
example
const values = [0, 20, 80 , 40]
const scale = RandomThings.closure.scale({min: 0 , max: 1 , values})
values.map(scale)
result
[ 0, 0.25, 1, 0.5 ]
Putting it all together
What you’ll probably want to do is to create a spreadsheet with some of these values populated for testing. Here’s an example of data generated using many of these functions.
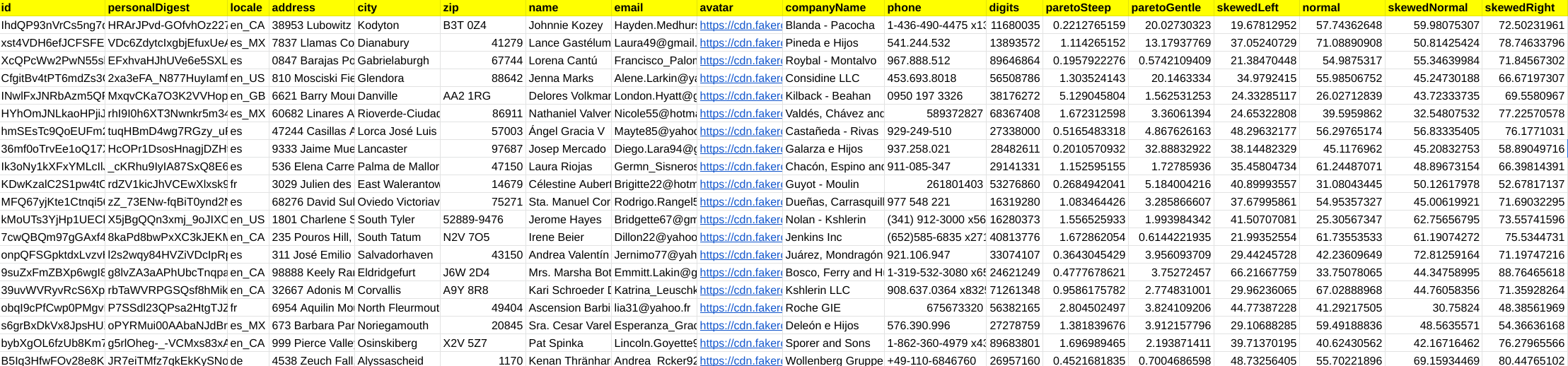
Generating sample data
First let’s create some faker and randomthings data
Dumping the data
Now we can use Handly helper for fiddler to simplify writing all this stuff out to a sheet.
Links
bmFaker : 1DDzzjMV4nbZyWAvkn8yPO9ENhUOg-YFA8v51uYbwNQuwbDxgs6ExEFV-
scrviz: scrviz link to bmFaker
github: https://github.com/brucemcpherson/bmFaker
usage: const { faker } = bmFaker
bmRandomThings: 1rwjs2dj7I6tBTGupHWJYdmRJwkoUYpsH1LZparS2llhT5XlToitoVfUp
scrviz: scrviz link to bmRandomThings
github: https://github.com/brucemcpherson/bmRandomThings
usage: const { RandomThings } = bmRandomThings
bmPreFiddler: 13JUFGY18RHfjjuKmIRRfvmGlCYrEkEtN6uUm-iLUcxOUFRJD-WBX-tkR
scrviz: scrviz link to bmPreFiddler