Reading the content
The Vision output will be a series of file in cloud storage. The objective is to assign approximate row and columns to all of that and to analyze what type of data is held in each cell. The structure of this app is

and it is executed like this
node language --path='a.pdf' --country="GB"
where the path is the one specifed at ocr time, and the country will be used for default localization (for example country code internaltionalization for phone numbers)
index.js
const argv = require('yargs').argv;
const languageServer = require('./languageserver');
languageServer.init({
mode: process.env.FIDRUNMODE || 'pv',
argv
});
languageserver.js
const secrets = require('../private/visecrets');
const languageOrchestrate = require('./languageorchestrate');
// wrapper to run the whole thing
const init = async ({ mode, argv }) => {
languageOrchestrate.init({ mode });
await languageOrchestrate.start({ mode, argv });
}
module.exports = {
init
};
anguageorchestrate.js
This process orchestrates a number of apis to try to assign meaning (a purpose) to each text item identified, each step enriching what we know about each text item.
const languageContent = require('./languagecontent');
const languageText = require('./languagetext');
const {getPaths} = require('../common/vihandlers');
// manages orchestration after vision api
const init = ({mode}) => {
languageContent.init({mode});
languageText.init({mode});
};
const start = async ({mode, argv}) => {
// for convenience - there's a common way to get all the file names/paths
// the bucket is specified in visecrets and the initial source path here
let {path, country: defaultCountry} = argv;
// TODO maybe mandate this arg later
defaultCountry = defaultCountry || 'GB';
const paths = getPaths({
pathName: path,
mode,
});
const {gcsContentUri, gcsDataUri} = paths;
// now clean up and extract the text from the vision response
const gcsTextUri = gcsContentUri;
// get the contects from storage that the vision step created
const contents = await languageText.getContents({gcsTextUri, mode});
// organize the ocr
const cleanCells = await languageText.start({contents, defaultCountry});
// now entity analysis using natural language api
const entities = await languageContent.start({
content: cleanCells.map(cell => cell.cleanText).join(','),
});
// now associate the mentions back to the original items
const assignedEntities = await languageText.assignEntities({
cleanCells,
entities,
});
// now get more info from google knowledge graph and attach to each emtity
const assignedMids = await languageText.getMids({assignedEntities});
// but we'll skip the bounding box info now
// finally write the whole thing to storage
return Promise.all([
languageText.writeResult({
data: {
mode,
paths,
defaultCountry,
content: assignedMids.map(f => {
f.texts = f.texts.map(g => {
delete g.bb;
return g;
});
return f;
}),
},
gcsDataUri,
mode,
}),
]);
};
module.exports = {
init,
start,
};
languageText.js
Organizes the data throw proximity. It also uses a number of APIS to identify common formats for phone numbers, email addresses and so on, as well as looking up my own GraphQL API to recognizes application specific entities.
The difference between breaks in words and breaks in entities.
Telling the difference between “Mike London” and “Mike” from “London” is a typical problem here. We can’t use ‘columns’ because that concept doesn’t exist except through fuzzy matching of bouding box co-oridinates, and in any case a document may well contain multiple formats which would confuse any attempt to columnize. Luckily, Vision provides the concept of ‘breaks’- these are
'EOL_SURE_SPACE', 'SURE_SPACE', 'LINE_BREAK', 'SPACE'
Each word consists of symbols (the letters of the word) and sometime a break property which gives a clue as to whether this is a phrase containing a space, or a bigger space indictating a different entity.
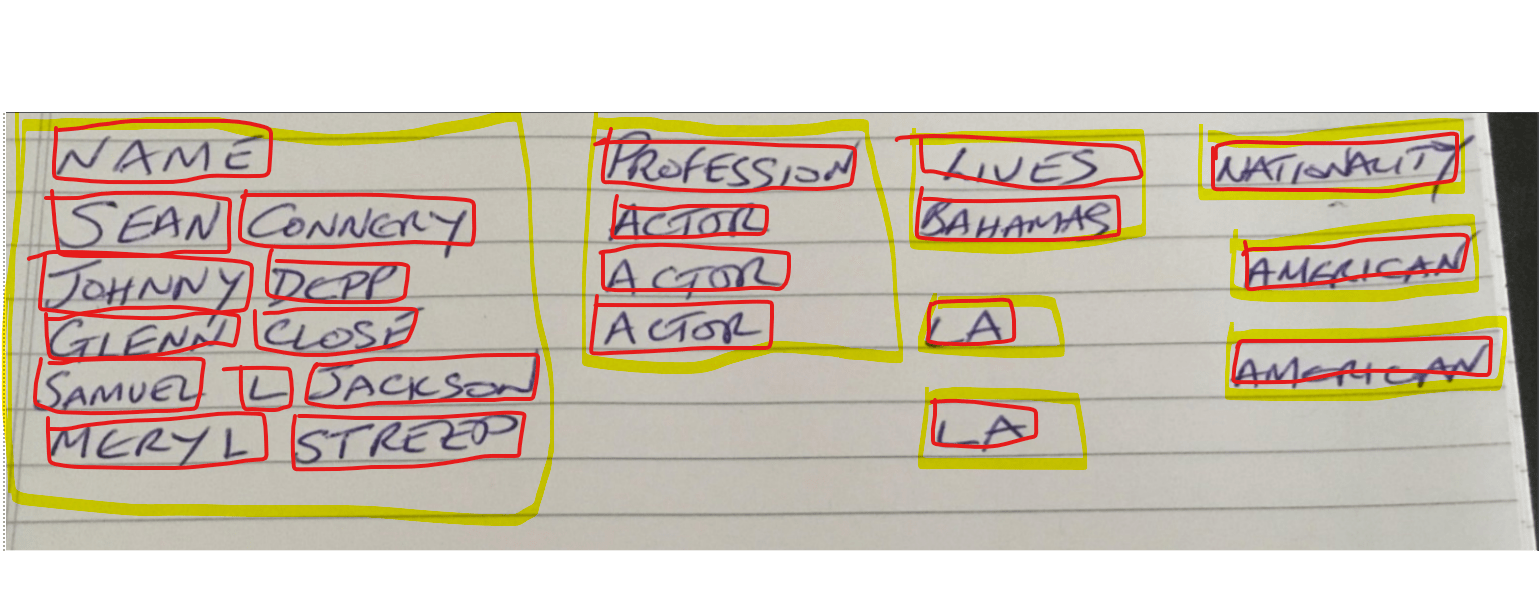
The results of these APIs are ‘scored’ to come up with the most likely role for an entity – for example
a phone number
+1 234 567 890
a name
Sean Connery
a place
The Bahamas
a profession
Actor
const storageStream = require('../common/storagestream');
const kgSearch = require('../common/kgsearch');
const {joinCellTexts, joinSymbols} = require('../common/viutils');
const {clues} = require('../private/visecrets');
const {
checkPhoneNumber,
joinPersonName,
checkProfession,
checkCompany,
getFuseProfession,
getFuseCompany,
checkEmail,
checkDate,
} = require('../common/vihandlers');
const buildLookups = require('../common/buildlookups');
let lookups = null;
// this does all the text fiddling and is the most complex area
const getContents = async ({gcsTextUri, mode}) =>
await storageStream.getFilesContents({
gcsUri: gcsTextUri,
mode,
});
// write the final result to storage
const writeResult = async ({data, gcsDataUri, mode}) =>
storageStream.streamContent({name: gcsDataUri, content: data, mode});
// get creds for knowledge graph search
// note that an api key is needed
const init = ({mode}) => {
kgSearch.init({mode});
buildLookups.init({mode});
lookups = buildLookups.start({mode});
};
// entry point
const start = async ({contents, defaultCountry}) => {
// flatten everything - the vision API content is convoluted
const cells = makeCells({contents});
// now cluster these into rows
const rows = clusterRows({cells});
// now cluster the rows into columns, for tabular presentation if needed
const columns = clusterColumns({cells});
// now we have decided how many columns, lets allocate them to actuall cells
allocateColumns({columns, rows});
// now attach row and column numbers to the final result
const attachedNumbers = attachNumbers({cells, rows, columns});
// we need the result of lookups
const [professionLookups, companyLookups] = await lookups;
const fuseProfession = getFuseProfession({professionLookups});
const fuseCompany = getFuseCompany({ companyLookups });
// finally clean up the text for use in the natrual language api
const cleanCells = clean({
cells: attachedNumbers,
defaultCountry,
fuseProfession,
fuseCompany,
});
return cleanCells;
};
// just get rid of white space/punctuation/join numbers etc.
const clean = ({cells, defaultCountry, fuseProfession, fuseCompany}) => {
return cells.map(cell => {
const s = joinCellTexts({cell})
.trim()
.replace(/\s?['"]\s?/g, '')
.replace(/\.$/, ' ')
.replace(/[,_\*]/g, ' ')
.replace(/\s+/g, ' ')
.trim();
// now get rid of anything thats just clearly noise
cell.cleanText = clues.nonsense.some(f => s.match(f)) ? '' : s;
// do any noise trimming
clues.trim.forEach(f => cell.cleanText = cell.cleanText.replace(f, ''));
// best checks on content
const phone = checkPhoneNumber({text: cell.cleanText, defaultCountry});
const person = joinPersonName({text: cell.cleanText});
const profession = checkProfession({text: cell.cleanText, fuseProfession});
const company = checkCompany({text: cell.cleanText, fuseCompany});
const email = checkEmail({text: cell.cleanText});
const dt = checkDate({text: cell.cleanText});
cell.clues = {
mobile:
phone.valid && phone.type === 'mobile'
? {...phone, embellished: phone.number.international}
: null,
phone: phone.valid
? {...phone, embellished: phone.number.international}
: null,
person: person.likely ? {...person, embellished: person.joined} : null,
profession: profession.valid
? {...profession, embellished: profession.searches[0].item.name}
: null,
email: email.valid ? {...email, embellished: email.text} : null,
date: dt.valid ? {...dt, embellished: dt.iso} : null,
company: company.valid
? {...company, embellished: company.searches[0].item.name}
: null,
};
return cell;
});
};
// use knowedge graph to get more details
const getMids = async ({assignedEntities}) => {
// do a single fetch on the knowledge graph with all the mids at once
const mids = assignedEntities.reduce((p, cell) => {
const mid = cell.entity && cell.entity.metadata && cell.entity.metadata.mid;
// dedup and record
if (mid && p.indexOf(mid) === -1) p.push(mid);
return p;
}, []);
// TODO - check - is there a max to the number of mids at once - do we need to chunk this?
// now we've collected all known mids, attack the knowledge graph
const kg = await kgSearch.search({mids});
const midItems = (kg && kg.data.itemListElement) || [];
// so now we have data from knowledge graph
return assignedEntities.map(cell => {
const mid = cell.entity && cell.entity.metadata && cell.entity.metadata.mid;
if (mid) {
kmid = 'kg:' + mid;
// if this is known mid, its possible now attach the definition
cell.kg = midItems
.filter(f => f['@type'] === 'EntitySearchResult')
.map(f => f.result)
.find(f => f['@id'] === kmid);
}
return cell;
});
};
// assign entities where they were classified
// the entity analysis is disassociated from the original text - have to find it again in the original
const assignEntities = ({cleanCells, entities}) => {
entities.forEach(entity => {
// reassociate with each mention
cleanCells.forEach(cell => {
if (entity.name === cell.cleanText) {
const {metadata, type} = entity;
cell.entity = {
metadata,
type,
};
}
});
});
return cleanCells;
};
// sometimes we get a separator that should be used as if it were a sure_space
const PROXY_BREAKS = ['|', ':', '>'];
// this means we can get rid of any proxy's from the text
const PROXY_DISPOSE = true;
// this gets rid of any text thats just blanks
const BLANK_DISPOSE = true;
/*
* although the final result will be thought of as 'row based'
* that concept doesnt exist in the initial image
* so instead we need to think in terms of cells that can later be linked
* by the affinity of their normalized vertices
* so there's no point in keeping the original complex layout
* just flatten into a collection of cells
*/
const makeCells = ({contents}) => {
return contents.reduce((cells, file, fileIndex) => {
const {content} = file;
content.responses.forEach((f, index) => {
// vsion cant hanfle for than 1000 pages so use that as false spearator
const pageIndex = index + fileIndex * 1000;
// its already paginated within each response, so there's only 1 page as far as i can tell
const {pages} = f.fullTextAnnotation;
pages.forEach((c, pIndex) => {
if (pIndex) throw 'should only be 1 page per response';
c.blocks.forEach((f, blockIndex) => {
// it uens out that there is only 1 paragraph inside a block
f.paragraphs.forEach((g, paragraphIndex) => {
// a paragraph can be used asa container for columnwise data
const parabb = makebb({
nv: g.boundingBox.normalizedVertices,
pageIndex,
blockIndex,
paragraphIndex,
pIndex,
});
// look through the rows and see where they best fit
let cell = null;
g.words.forEach((h, wordIndex, arr) => {
const key = `${pageIndex}-${pIndex}-${blockIndex}-${paragraphIndex}-${wordIndex}`;
const bb = makebb({
nv: h.boundingBox.normalizedVertices,
pageIndex,
blockIndex,
paragraphIndex,
wordIndex,
pIndex,
parabb,
key,
});
// not doing any further processing at this time, just reorganize into cells
const text = joinSymbols({word: h});
// the breaks are used to determine which words go in a cell
const breaks = h.symbols
.map(
t =>
t.property &&
t.property.detectedBreak &&
t.property.detectedBreak.type
)
.filter(t => t);
// this is a character forced sure space
if (PROXY_BREAKS.indexOf(text.slice(-1)) !== -1) {
breaks.push('PROXY');
}
// intialize a new cell if needed
cell = cell || {
texts: [],
sourceLocation: {
pageIndex,
blockIndex,
paragraphIndex,
},
};
// register this one
let cleaned = text;
if (
PROXY_DISPOSE &&
breaks.find(t => ['PROXY'].indexOf(t) !== -1)
) {
cleaned = cleaned.slice(0, -1);
}
if (!BLANK_DISPOSE || cleaned.replace(/\s+/, '').length) {
cell.texts.push({
text: cleaned,
bb,
separator: breaks[0] === 'SPACE' ? ' ' : '',
});
}
// if its the end of a cell then record this as a completed cell
if (
breaks.find(
t =>
[
'EOL_SURE_SPACE',
'SURE_SPACE',
'LINE_BREAK',
'PROXY',
].indexOf(t) !== -1
)
) {
if (cell.texts.length) {
cells.push(cell);
}
cell = null;
}
});
});
});
});
});
return cells;
}, []);
};
// just find the bb closest to the middle
const closestMiddlebb = (a, b, target) =>
a && b
? Math.abs(a.bb.ubox.center.middle.y - target.ubox.center.middle.y) <
Math.abs(b.bb.ubox.center.middle.y - target.ubox.center.middle.y)
? a
: b
: a || b;
// just find the bb closest to the left
const closestLeftbb = (a, b, target) =>
a && b
? Math.abs(a.bb.raw.topLeft.x - target.raw.topLeft.x) <
Math.abs(b.bb.raw.topLeft.x - target.raw.topLeft.x)
? a
: b
: a || b;
/**
* This is not a exact science
* the objective is to cluster together cells that appear on a similar y axis
* and give them the same rowId
*/
const clusterRows = ({cells}) => {
// sort into heights so we do the tallest sections first
return (
cells
.sort((a, b) => a.texts[0].bb.ubox.height - b.texts[0].bb.ubox.height)
.reduce((rows, cell) => {
// see if we have one already
const {bb} = cell.texts[0];
let row = rows
.filter(
f =>
bb.pageIndex === f.bb.pageIndex &&
bb.ubox.center.middle.y <= f.bb.ubox.center.bottom.y &&
bb.ubox.center.middle.y >= f.bb.ubox.center.top.y
)
// now find the nearest to the center of all rows collected so far
.reduce((q, t) => closestMiddlebb(q, t, bb), null);
// now row will be pointing to the nearest existing row or will be null
// if no match then add it
if (!row) {
row = {
count: 0,
cells: [],
id: rows.length,
bb,
};
rows.push(row);
}
row.cells.push(cell);
// keep them sorted in column order for convenience
row.cells.sort(
(a, b) => a.texts[0].bb.raw.topLeft.x - b.texts[0].bb.raw.topLeft.x
);
// cross ref for later
cell.rowId = row.id;
return rows;
}, [])
// sort in row order
.sort(
(a, b) =>
a.bb.pageIndex +
a.bb.ubox.center.middle.y -
(b.bb.pageIndex + b.bb.ubox.center.middle.y)
)
.map((row, i) => {
row.rowNumber = i;
return row;
})
);
};
const closeColumn = ({bb, rightbb, text, tbb}) => {
// this is only approximate as there may have been some cleared away proxy separators
const charSize = (rightbb.raw.topRight.x - bb.raw.topLeft.x) / text.length;
// allow a tolerance of 2 characters
const tolerance = charSize * 2;
return Math.abs(bb.raw.topLeft.x - tbb.bb.raw.topLeft.x) <= tolerance;
};
/**
*
* put columns in the best match by row
*/
const allocateColumns = ({columns, rows}) => {
rows.forEach(row => {
row.cells.forEach(cell => {
const bb = cell.texts[0].bb;
const closeColumn = columns.reduce(
(q, t) => closestLeftbb(q, t, bb),
null
);
if (!closeColumn) {
console.log(
'failed to find close column for',
joinCellTexts({cell}, ' row ', row.rowNumber)
);
} else {
const t = row.cells.find(f => closeColumn.id === f.columnId);
if (t) {
console.log(
'dropping cell for',
joinCellTexts({cell}),
' row ',
row.rowNumber,
' already occupied by ',
joinCellTexts({cell: t})
);
// this means it'll get ignored in a sheet render
cell.columnId = -1;
} else {
cell.columnId = closeColumn.id;
}
}
});
});
};
/**
*
* this is post processing to attach column and row numbers to the cells after all sorting etc
*/
const attachNumbers = ({cells, rows, columns}) => {
// make lookups
const cls = columns.reduce((p, c) => {
p[c.id] = c.columnNumber;
return p;
}, []);
const rws = rows.reduce((p, c) => {
p[c.id] = c.rowNumber;
return p;
}, []);
return cells.map(cell => {
cell.rowNumber = rws[cell.rowId];
// this will happen if the data could not be allocated to any column
cell.columnNumber =
cell.columnId === -1 ? cell.columnId : cls[cell.columnId];
cell.id = cell.rowId * 10000 + cell.columnId;
return cell;
});
};
/**
* This is not a exact science
* the objective is to cluster together cells that appear on a similar x axis
* the pbig problem here is that the source data is probably not columnized
* so we need an arbitrary measure of what 'close' means
* I'm giving it 2 characters adjusted for font size
*/
const clusterColumns = ({cells}) => {
// sort into leftmost so leftmost happens first
return (
cells
.sort(
(a, b) => a.texts[0].bb.ubox.topLeft.x - b.texts[0].bb.ubox.topLeft.x
)
.reduce((columns, cell) => {
// see if we have one already
const text = joinCellTexts({cell});
const {bb} = cell.texts[0];
const {bb: rightbb} = cell.texts[cell.texts.length - 1];
let column = columns
// only consider boxes it lies in
// and allow a little bit of tolerance
.filter(tbb => closeColumn({bb, rightbb, text, tbb}))
// now find the nearest of all columns collected so far
.reduce((q, t) => closestLeftbb(q, t, bb), null);
if (!column) {
column = {
bb,
rightbb,
id: columns.length,
col: bb.raw.topLeft.x,
columnId: -1,
};
columns.push(column);
}
return columns;
}, [])
// sort in column order
.sort((a, b) => a.col - b.col)
.map((column, i) => {
column.columnNumber = i;
return column;
})
);
};
const makeUbox = ({nv, parabb}) => {
// this is the raw bb of the word nv (normalized vertices)
const raw = {
topLeft: {
x: nv[0].x,
y: nv[0].y,
},
topRight: {
x: nv[1].x,
y: nv[1].y,
},
bottomRight: {
x: nv[2].x,
y: nv[2].y,
},
bottomLeft: {
x: nv[3].x,
y: nv[3].y,
},
};
// but we'll use the paragraph x co-ordinates to line those in the same paragraph up
const pbox = {
topLeft: {
x: parabb ? parabb.raw.topLeft.x : nv[0].x,
y: nv[0].y,
},
topRight: {
x: parabb ? parabb.raw.topRight.x : nv[1].x,
y: nv[1].y,
},
bottomRight: {
x: parabb ? parabb.raw.bottomRight.x : nv[2].x,
y: nv[2].y,
},
bottomLeft: {
x: parabb ? parabb.raw.bottomLeft.x : nv[3].x,
y: nv[3].y,
},
};
// now create an unskewed parabound - this is what we'll use for most calculations
// the normalized vertices seem to adjust for skew - but in case not, max/min top and bottom
// to draw a rectangle around the extremities.
const {topLeft: pTopLeft} = pbox;
const {topLeft, topRight, bottomLeft, bottomRight} = raw;
// there's a mixture of paragraph and raw here on purpose.
// use the paragraph left edge for left dimensions
const ubox = {
topLeft: {
x: Math.min(pTopLeft.x, topLeft.x),
y: Math.min(topLeft.y, topRight.y),
},
topRight: {
x: Math.max(topRight.x, bottomRight.x),
y: Math.min(topLeft.y, topRight.y),
},
bottomRight: {
x: Math.max(topRight.x, bottomRight.x),
y: Math.max(bottomLeft.y, bottomRight.y),
},
bottomLeft: {
x: Math.min(pTopLeft.x, bottomLeft.x),
y: Math.max(bottomLeft.y, bottomRight.y),
},
};
// the width/height/center is of the unskewed box
ubox.width = ubox.topRight.x - ubox.topLeft.x;
ubox.height = ubox.bottomRight.y - ubox.topRight.y;
ubox.center = {
top: {
x: ubox.topLeft.x + ubox.width / 2,
y: ubox.topLeft.y,
},
middle: {
x: ubox.topLeft.x + ubox.width / 2,
y: ubox.topLeft.y + ubox.height / 2,
},
bottom: {
x: ubox.bottomLeft.x + ubox.width / 2,
y: ubox.bottomLeft.y,
},
};
return {
raw,
pbox,
ubox,
nv,
};
};
const makebb = ({
nv,
pageIndex,
blockIndex,
paragraphIndex,
wordIndex,
pIndex,
parabb,
key,
}) => {
// so we need to fiddle with the bb box to unskew it
const ubox = makeUbox({nv, parabb});
return {
key,
...ubox,
blockIndex,
pageIndex,
paragraphIndex,
wordIndex,
pIndex,
parabb,
};
};
module.exports = {
start,
getContents,
clean,
assignEntities,
writeResult,
getMids,
init,
};
languageContent – uses the Google Natural Language API to do some entity analysis on text content. This can return an entity ‘mid’ which is a lookup key to the Google Knowledge Graph if an entity is known – for example “Sean Connery” has an entry in the Knowledge Graph)
See Making sense of Ocr for next steps
Related
This example is actual part of a much larger workflow which makes use of a range of APIS. If you found this useful, you may also like some of the pages here.
Since G+ is closed, you can now star and follow post announcements and discussions on github, here