This is the first step in Making sense of Ocr – getting a pdf turned into a JSON map.

Mechanics
Organization

node ocr --path='a.pdf'
This will create one or more files (depending on the document complexity), like this

index.js
const argv = require('yargs').argv;
const ocrServer = require('./ocrserver');
ocrServer.init({
mode: process.env.FIDRUNMODE || 'lv',
argv
});
ocrserver.js
const ocrOrchestrate = require('./ocrorchestrate');
// wrapper to run the whole thing
const init = async ({mode, argv}) => {
ocrOrchestrate.init({mode});
await ocrOrchestrate.start({mode, argv});
};
module.exports = {
init,
};
ocrorchestrate.js
There is come common code shared across each step. getPaths construct standard gcs path uris from the base source file for each step. In this case we are interested in the gs://bucketname/filename to use for the source data and the folder to place the ocr results in (derived from the --path argument). It’ll be covered separately on a section on the common code.
const ocrVision = require('./ocrvision');
const {getPaths} = require('../common/vihandlers');
// manages orchestration of vision api
const init = ({mode}) => {
ocrVision.init({mode});
};
const start = async ({mode, argv}) => {
// for convenience - there's a common way to get all the file names/paths
// the bucket is specified in visecrets and the initial source path here
const { path } = argv;
const {gcsSourceUri, gcsContentUri} = getPaths({
pathName: path,
mode,
});
await ocrVision.start({
gcsSourceUri,
gcsContentUri,
});
};
module.exports = {
init,
start,
};
ocrvision.js
const secrets = require('../private/visecrets');
const vision = require('@google-cloud/vision').v1;
// does the vision annotation
let client = null;
const init = ({ mode }) => {
client = new vision.ImageAnnotatorClient({
credentials: secrets.getGcpCreds({mode}).credentials,
});
};
const start = async ({gcsSourceUri, gcsContentUri}) => {
const inputConfig = {
mimeType: 'application/pdf',
gcsSource: {
uri: gcsSourceUri,
},
};
const outputConfig = {
gcsDestination: {
uri: gcsContentUri
},
};
const features = [{type: 'DOCUMENT_TEXT_DETECTION'}];
const request = {
requests: [
{
inputConfig: inputConfig,
features: features,
outputConfig: outputConfig,
},
]
};
// OCR it
console.log('starting ', features, ' on ', inputConfig, ' to ', outputConfig);
const [operation] = await client.asyncBatchAnnotateFiles(request);
const [filesResponse] = await operation.promise();
const destinationUri =
filesResponse.responses[0].outputConfig.gcsDestination.uri;
return filesResponse;
};
module.exports = {
init,
start
};
The result will be a folder on cloud storage in which a collection of json files, with each file holding the analysis of multiple pdf pages. Since this initial example is small, there will only be one file, with one page in it.
"responses": [{
"fullTextAnnotation": {
"pages": [{
"property": {
"detectedLanguages": [{
"languageCode": "en",
"confidence": 0.8
}, {
"languageCode": "es",
"confidence": 0.05
}]
},
"width": 792,
"height": 612,
"blocks": [{
"boundingBox": {
"normalizedVertices": [{
"x": 0.5997475,
"y": 0.01633987
}, {
"x": 0.7121212,
"y": 0.01633987
}, {
"x": 0.7121212,
"y": 0.1127451
}, {
"x": 0.5997475,
"y": 0.1127451
}]
},
"paragraphs": [{
"boundingBox": {
"normalizedVertices": [{
"x": 0.5997475,
"y": 0.01633987
}, {
The slightly surprising thing to note is that the concept of ‘rows’ and ‘columns’ don’t exist. Instead there are blocks, paragraphs, symbols and bounding boxes to deal with to be able to reconstruct a tabular like format.
v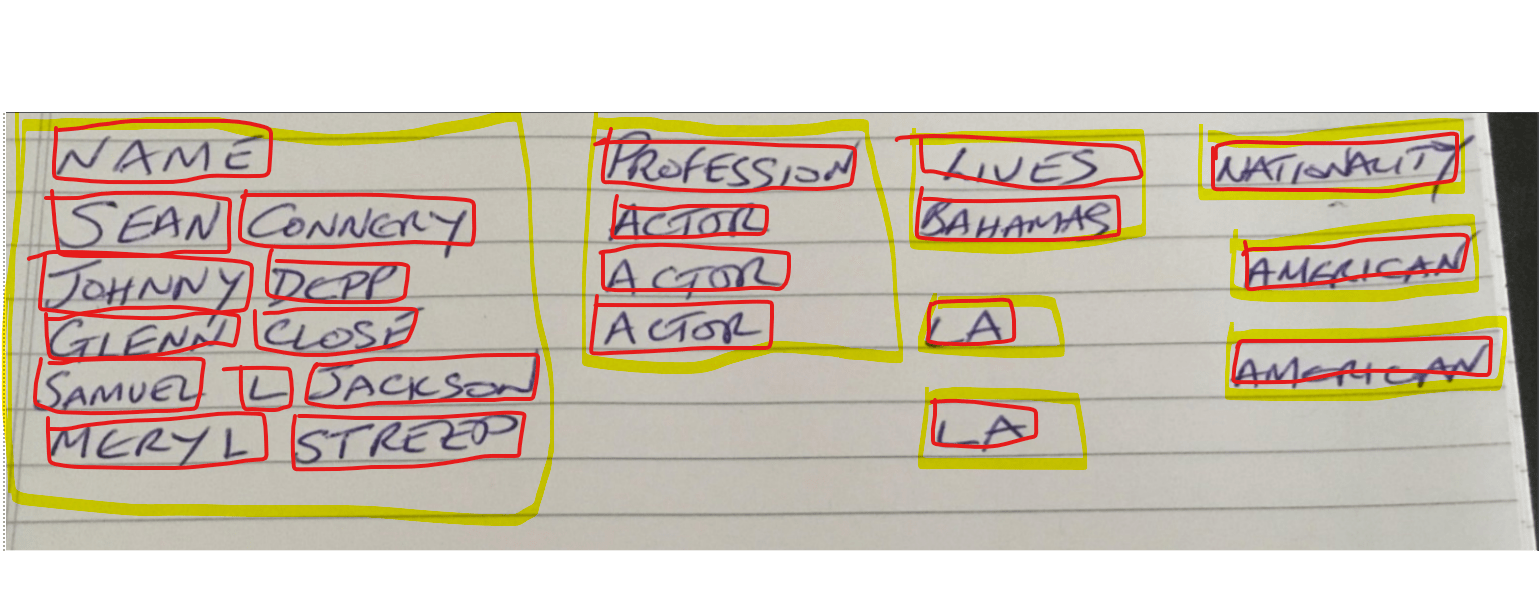
Related