Normally I’d want to use the Rest to Excel library to get data into Excel, but sometimes you have to resort to web scraping. My preferred route is to do something in scraperwiki, then use a rest query to get the scraped wiki into Excel (or Google Apps)
But you need to know python, R, PHP or more recently node.js, to be able to do that – these are the languages that scraperWiki supports. None are particularly hard to learn to the degree you need to be able to get on and do some scraping, but if you don’t want to do that, here’s an example of scraping using VBA, and some of the libraries on this site.
In particular, we’re going to use regex. This is exactly what I’d do on scraperWiki, but it’s often overlooked that VBA has pretty good regex support too. A simplified approach to regex was covered in Regular Expressions, but for this task we’ll have to do some thing a little more complex, as was introduced in pinyin conversions
You’ll find the code in cDataSet.xlsm, downlable from Downloads
The source data
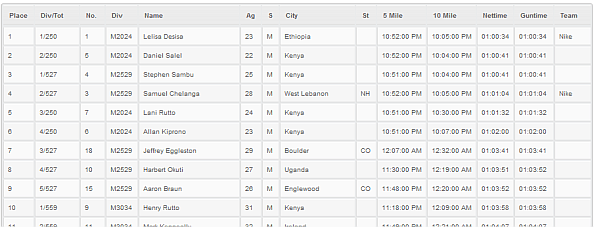
For this example, we’ll try to get the results of the Boston Half Marathon, available here. The objective is to get the thing into an Excel table – and as a bonus I’ll also make an interactive Google Table and a static table for loading to a web site too.
A snippet below
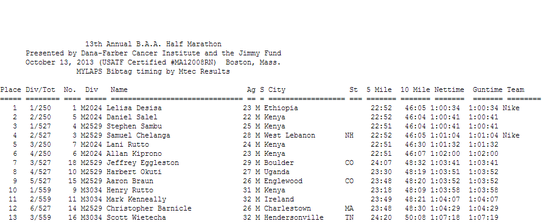
I’m using this one, because it’s a bit trickier than the usual scraping activities where data is organized into tables – what we have here is some fairly unformatted data enclosed in <pre> </pre> tags, so we’ll be able to use some simple regex to sort it out.
How to identify your data
I normally use Chrome developer tools to take a look at the web page first. In this case,

Using those, I’ve traced the data I want to be within a <pre></pre> tag. This is pretty unusual – you would have expected this kind of data to be nicely formatted in an html table. Instead we have, essentially a snapshot of a printed report.
I’m using the cBrowser class, since I’ve already dealt with the mechanics of browser navigation elsewhere.
URL = "http://www.coolrunning.com/results/13/ma/Oct13_13thAn_set1.shtml" ' get the web page Set cb = New cBrowser cb.init().Navigate URL, , False
When we return we’ll have a nicely populated html document. We can find the text in the <pre> class like this. This is a one off scraper, so Im not going to bother too much about error handling.
' its the only <pre> in the page
Set nodeList = cb.elementTags("pre")
Set node = nodeList(0)
' node should contain the results
' kind of wierd its not an html table
Debug.Assert InStr(1, node.innerText, "Half Marathon") > 0
Finding the header
One thing I noticed was that the headings are underlined with equals signs. If I could find them, I’d know where the data started, and not only that, but the width of each column.
This regex snippet will return a single match with the row of === markers. This will tell me not only where the headings are (on the row before), but where the data is (starting the row after), and where each column begins – at the beginning of each block of “==”
' a simple regex will find the title distribution Set rx = New RegExp With rx .ignorecase = True .Global = True .Pattern = "=.*(?=\s)" End With Set matches = rx.execute(node.innerText) ' now we should have a single match with all about where the title underlining is ' looks like this ===== ======== ==== ===== ' except that all but the first one are misaligned by 1 for the data Debug.Assert matches.count = 1 Set match = matches(0)
Splitting up the headers
Now we can use another regex to split the “==” into discrete column heading positions, and then work backwords to extrapolate where the header row begins and ends
' we'll split that up into seperate sections rx.Pattern = "=+(?=\s)" Set heads = rx.execute(Mid(node.innerText, match.FirstIndex + 1, match.Length - 1)) ' we can get the header line p = 0 For i = match.FirstIndex To 1 Step -1 If (Mid(node.innerText, i, 1) = vbLf) Then p = p + 1 If (p = 2) Then ' we're at the \n before the header row headerRow = Mid(node.innerText, i + 1, match.FirstIndex - i - 2) Exit For End If End If Next i
Populating the sheet
Now we can populate the headers and data in the sheet, using the “==” ruler as guide for where the columns begin and end. We’ll use another regex to split the data into separate lines. Finally I did notice that the headings are a little misaligned to the data, so I need to make a small correction for that too.
'clear the worksheet
Application.Calculation = xlCalculationManual
Set r = firstCell(wholeSheet("marathonresults"))
r.Worksheet.Cells.ClearContents
p = 0
For Each item In heads
r.Offset(0, p).value = Trim(Mid(headerRow, item.FirstIndex + 1, item.Length))
p = p + 1
Next item
' and the data
rx.Pattern = ".+(?=\n|$)"
' get the start point of the data
k = match.FirstIndex + match.Length
While (Mid(node.innerText, k, 1) <> vbLf)
k = k + 1
Wend
Set dats = rx.execute(Mid(node.innerText, 1 + k))
t = 0
For Each data In dats
p = 0
t = t + 1
For Each item In heads
k = item.FirstIndex + 1
' the headings, except the first, are actually misaligned by 1
If k > 1 Then k = k - 1
r.Offset(t, p).value = Trim(Mid(data.value, k, item.Length))
p = p + 1
Next item
Next data
The result
Here we have it- 6000+ lines scraped and copied to Excel.
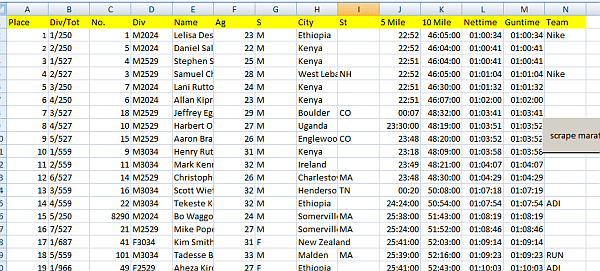
Visualizing the table
So how about we turn that into a google visualization. We can use Visualizing tables to make one from this data. The code is a one liner.
Public Sub vizMaratahonGoogle() tableToHtml "marathonresults", , , , "google" End Sub
and it gives us a very nice interactive version of that data,
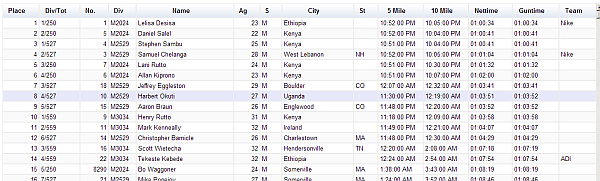
that can be hosted on a web site – You can see it here.
Alternatively, you could create a static version – another one liner
Public Sub vizMaratahonStatic() ' a static html rendering tableToHtml "marathonresults", , , , "static" End Sub
also nicely formatted, and hosted here.
The complete code
For help and more information, you can join the forum, follow me on Twitter or follow the blog.