In Blistering fast file streaming between Drive and Cloud Storage using Cloud Run I showed how you could use Cloud Run to hand off transfers between Drive and Cloud Storage to make them faster and more reliable. This is particularly pertinent for Apps Script where larger file transfers can cause timeouts and unexpected runtime errors. In this article I’ll show an example of how to use Cloud Run transfers directly from Apps Script.
Prequisite
Before you can do this you should set up and test your Cloud Run Proxy transfer service, as described in Blistering fast file streaming between Drive and Cloud Storage using Cloud Run and test it out using curl. You’ll need the service accounts that you set up there to give to Apps Script, and of course the endpoint for your deployed cloud run service.
We’ll assume that you’ve put those service accounts somewhere on drive so that Apps Script can get them. If you get stuck setting up your own Cloud Run service, I may give you limited access to a running service, but you’ll still need to create your own service accounts to access your own Drive and/or Cloud storage first. Ping me at bruce@mcpher.com
Setup
Just to make it easier to work with folders on drive, I’m using A handier way of accessing Google Drive folders and files from Apps Scripts if you’re using these snippet you’ll need that library.
Apps Script test
This will copy a bunch of random files between gcs and drive each way.
Getting the service accounts
The first part is to get the content of the downloaded service account json files so we can pass them to cloud run to enable it to access your Drive and GcS files. Since I’m planning to use both GCS and Storage and I have separate service accounts from each, I need to get and combine the content.
That will generate the first part of the parameter defintion to pass over to the Cloud Run service.
Getting the work package
To give it a good test, I’m going to send over a mixture of file types and sizes in each direction. The cloud run service supports both ID and Path specification for Drive files, so I’m going to send over both versions.
This will format 2 sets of transfers to try out both directions. Remember that the service will do all the transfers in a work package simutaneously, so we should expect this to all run very quickly.
Note that if any folders specified don’t exist already, the cloud run service will create them.
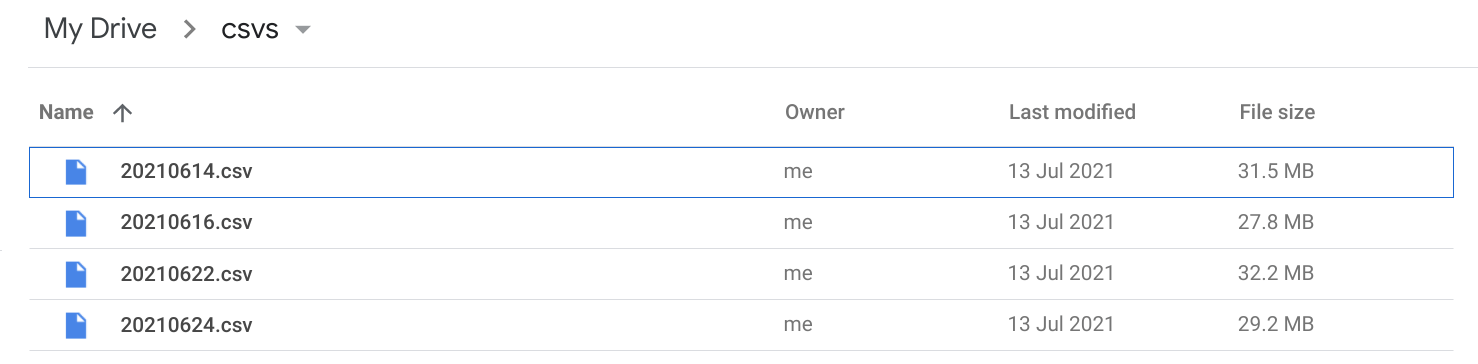
files from Drive
Here’s the files being transferred from Drive – I’m making 2 copies from Drive to GCS. One using the file IDS, and another using the file paths and leaving it to the Cloud run service to figure out the Ids. The results should be the same.
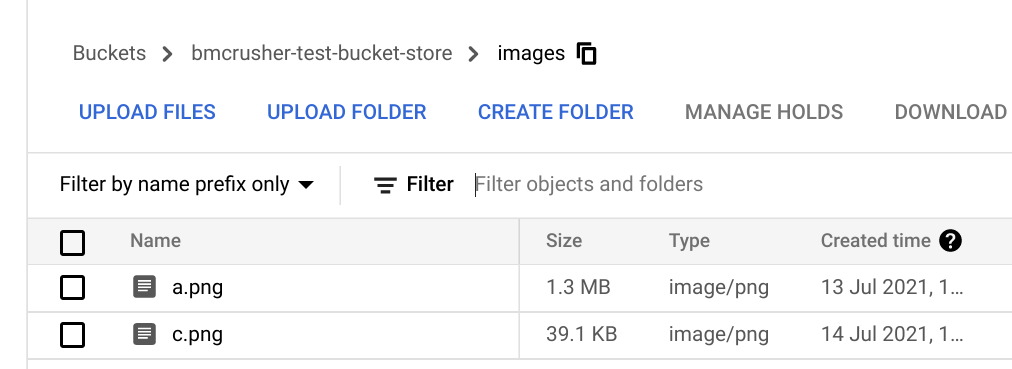
files from Gcs
Here are the files being transferred from Gcs to Drive
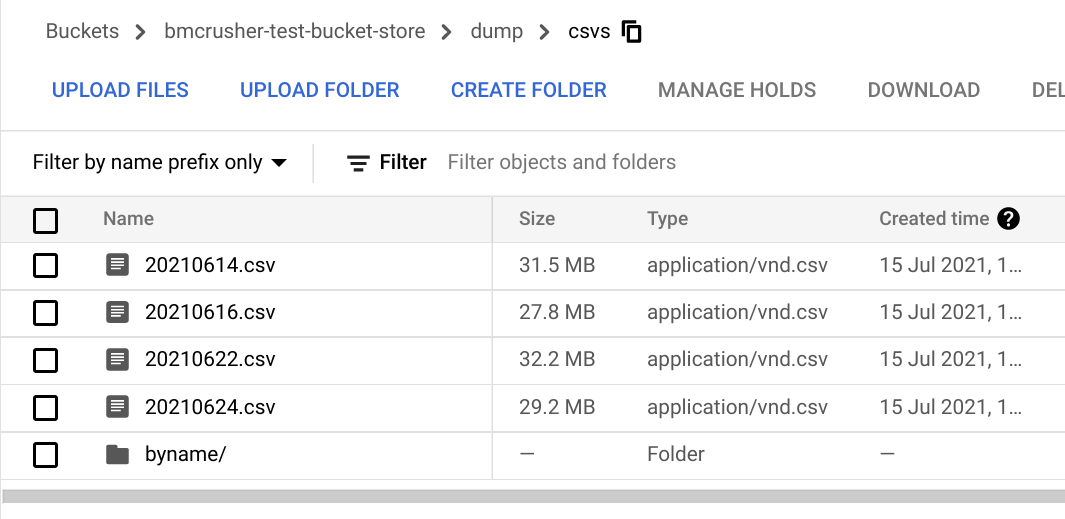
The copied files
On drive

on gcs

The log file
We can check progress on cloud console/cloud run/logs

The total run time was about 12 secs to transfer about 250mb across 10 files. Not Bad!
The response
The service returns a summary of what was transferred and how long it took for each one – so if you’ve copied files from GCS to Drive you can pick up the generated fileIds from here.
links
bmFolderFun
library: 16NWIRmwJJY_wN4erx_QZA36_ssaB2GiKDPYebj7fjBU1SpVQlo9N_RA7
scrviz: https://scrviz.web.app?manifest=brucemcpherson%2FbmFolderFun%2Fappsscript.json
Setting up Cloud Run service
Blistering fast file streaming between Drive and Cloud Storage using Cloud Run