In scraping the scraper I showed how to get scraperwiki data into both Excel and Google Apps Script. More interestingly though, I was talking about data for which others had already done the legwork to create tables of data they had scraped from unstructured web pages and made publicly available. I thought maybe I should publish an occasional directory of interesting scrapes I came across.
Of course since these have been created by various unknown contributors, they may be plain wrong, out of date, disappeared or irrelevant, but for those of you have not yet used scraperwiki , it’s an interesting introduction to some of the data that is being extracted out there.
To take a look yourself you can of course use the downloadable excel and Google Apps Script version and download the data by giving its scraperwiki shortname in the scraperWikiData tab. Here’s a few from today’s scrape of the most recent 1000 scrapes.
| Scraper Wiki Short Name | Description | |
|
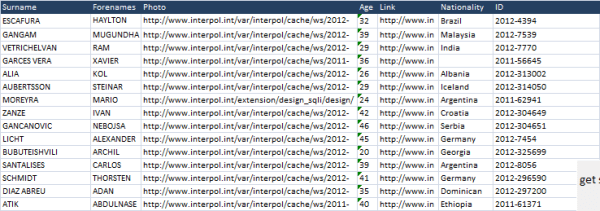
List of names, descriptions, photos, links etc of internationally wanted people | |
| 318_decc_speeches | uk government speeches content and details | |
| us-states_1 | list of US states, along with their short codes and numbers | |
| relief_web_disasters_timeline | list of disasters along with dates and details | |
| marriage_equality_scraper | list of UK members of parliament opinions on marriage equality | |
| paralympic_athletes_london_2012 | list of paralympic atheletes in London 2012 |
Here’s and extract from the first one. Thanks to S Woodard for publishing the scraper.
I’ll be adding to this from time to time, and you can find the most recent interesting scrapes directory here. If you come across any interesting includeworthy scrapes then please let me know by commenting or contacting me on the excel liberation forum.