Take a moment to read these if this is a new topic for you.
- Orchestration of Apps Scripts – parallel threads and defeating quotas
- Jobs, work, stages, threads and chunks
- Namespaces and App structure
Code is on github
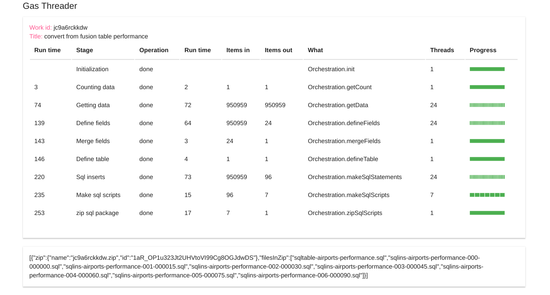
I’ll refer to this completed Job as I go through the work package set up.
Page Content
hide
Work
A work package defines the stages, their sequencing and how to split up the work in each stage. Each instance of a work package gets a unique ID which is used to associate the data from stage with its work package. Normally I would set up the package in a namespace named “Job”. This would also contain the parameters to reuse the Work package with various parameters that together would make up multiple jobs. Let’s look at the example stage definition for
![]()
{
stage: "sqlScripts",
stageTitle: "Make sql scripts",
// the maximum number of chunks to break the job into omit
maxThreads: 24,
// the minimum chunk size
minChunkSize: 15,
instances: {
namespace: "Orchestration",
method: "makeSqlScripts",
arg: fusion
}
},
Here’s what the properties mean
| Property | example value | purpose |
| stage | “sqlScripts” | used to refer to this stage from other stages |
| stageTitle | “Make sql scripts” | description appears in the dashboard |
| maxThreads | 24 | The maximum number of threads to run in parallel. If you don’t want to split up the work, use 1 |
| minChunkSize | 15 | The minimum number of items to include in a chunk. maxThreads, minChunkSize and the number of Items In will together control how the job is split and how many threads will ultimately be created |
| instances | Describes what to run server side for this stage | |
| .namespace | “Orchestration” | The namespace that contains the server side function. If the function is in the global space (I recommend putting all functions in a namespace), then use “” |
| .method | “makeSqlScripts” | The function or namespace method to execute server side |
| .arg | fusion | Any arguments specific to the this job. Passing different values will allow you to use the same work package for multiple purposes. These arguments will get passed to your function |
| skipReduce | false | Default is false. If true, a “real” reduce to combine the results of all the chunks in a stage is skipped, and future stages will access data in their uncombined form. |
| logReduce | false | It can be useful for debugging to examine the results from a stage. True will log them to the browser console |
| dataCount | “getData” | Can be used to identify the stage to get the count of input data to allocate across threads. Normally it’s the previous stage and can be omitted. |
Job
In this example application, I’m using the same work package to process 3 different Fusion tables. Use this pattern to create jobs that vary the work package by passing an argument with the changed parameters. Here’s the entire job workspace for the example application, and the pattern you should follow when creating Job and Work packages.
/**
* parameters to describe the work that needs to be done
* this example contains parameters for multiple similat jobs
*/
var Job = (function(ns) {
ns.getJob = function(job) {
// params for this job
const fusion = ns.jobs[job];
if (!fusion) throw "unknown job " + job;
return ns.getWork(fusion);
};
ns.jobs = {
locations: {
fusionTable: "airports",
fusionKey: "1Ug6IA-L5NKq79I0ioilPXlojEklytFMMtKDNzvA",
db: "airports",
table: "locations",
limit: 100,
folderId: "1h7qeysh2WzDuCNEJh6_qcqY_fTeHcByw",
maxr: 0,
tableCreate:true,
forceMap:{
"RowId":"SKIP"
}
},
performance: {
fusionTable: "US Air Carrier Flight Delays-On_Time_Performance",
fusionKey: "1aoTFJygMLOD0r-QsaKG5-4375VwQpwuGb18dMGw",
db: "airports",
table: "performance",
limit: 10000,
folderId: "1h7qeysh2WzDuCNEJh6_qcqY_fTeHcByw",
maxr: 0,
tableCreate:true,
forceMap:{
"ArrDelayMinutes" : "INT",
"DayofMonth": "INT",
"DepDelayMinutes" : "INT",
"Month": "INT",
"Year" :"INT",
"DepDelayMinutes":"INT",
"FlightDate":"TIMESTAMP",
"isLateDepart":"BOOLEAN",
"RowId":"SKIP"
}
},
carriers: {
fusionTable: "carriercodes",
fusionKey: "1pvt-tlc5z6Lek8K7vAIpXNUsOjX3qTbIsdXx9Fo",
db: "airports",
table: "carriers",
limit: 100,
folderId: "1h7qeysh2WzDuCNEJh6_qcqY_fTeHcByw",
maxr: 0,
tableCreate:true,
forceMap:{
"RowId":"SKIP"
}
}
};
ns.getWork = function(fusion) {
return {
title: "convert from fusion table " + fusion.table,
// future versions - a work id can be specified to rerun
// for now a new one will be generated each time
workId: "",
stages: [
{
stage: "init",
stageTitle: "Initialization",
instances: {
namespace: "Orchestration",
method: "init"
}
},
{
stage: "count",
stageTitle: "Counting data",
instances: {
namespace: "Orchestration",
method: "getCount",
arg: fusion
}
},
{
stage: "getData",
stageTitle: "Getting data",
// normally there's a reduce stage after each map
// but if the data is too big, you can do a fake reduce
// that only reduce links to the chunks, rather than copy it
// and use Server.getSlice to retrieve sections of data for a stage
skipReduce: true,
// the maximum number of chunks to break the job into omit for the default
maxThreads: 24,
// the min size of a chunk to avoid splitting job into inefficiently small chunks
// omit for default
minChunkSize: 200,
// the
instances: {
namespace: "Orchestration",
method: "getData",
arg: fusion
}
},
{
stage: "defineFields",
stageTitle: "Define fields",
// the maximum number of chunks to break the job into omit for the default
maxThreads: 24,
// the min size of a chunk to avoid splitting job into inefficiently small chunks
// omit for default
minChunkSize: 100,
logReduce:false,
instances: {
namespace: "Orchestration",
method: "defineFields",
arg:fusion
}
},
{
stage: "mergeFields",
stageTitle: "Merge fields",
// the maximum number of chunks to break the job into omit for the default
maxThreads: 1,
instances: {
namespace: "Orchestration",
method: "mergeFields"
}
},
{
stage: "defineTable",
stageTitle: "Define table",
// the maximum number of chunks to break the job into omit for the default
maxThreads: 1,
instances: {
namespace: "Orchestration",
method: "defineTable",
arg: fusion
},
logReduce:false
},
{
stage: "sqlInserts",
stageTitle: "Sql inserts",
// the maximum number of chunks to break the job into omit
maxThreads: 24,
// the minimum chunk size should try to match the limit size
// for how many inserts to do in 1 sql file
minChunkSize: fusion.limit,
// where to get the num items to work on
dataCount: "getData",
// dont bother reducing - there may be too many to deal with
// all at once
skipReduce: true,
instances: {
namespace: "Orchestration",
method: "makeSqlStatements",
arg: fusion
}
},
{
stage: "sqlScripts",
stageTitle: "Make sql scripts",
// the maximum number of chunks to break the job into omit
maxThreads: 24,
// the minimum chunk size
minChunkSize: 15,
instances: {
namespace: "Orchestration",
method: "makeSqlScripts",
arg: fusion
}
},
{
stage: "zipScripts",
stageTitle: "zip sql package",
// the maximum number of chunks to break the job into omit
maxThreads: 1,
instances: {
namespace: "Orchestration",
method: "zipSqlScripts",
arg: fusion
}
}
]
};
};
return ns;
})({});
Next
Previous
- Orchestration of Apps Scripts – parallel threads and defeating quotas
- Jobs, work, stages, threads and chunks
- Namespaces and App structure
Why not join our forum, follow the blog or follow me on Twitter to ensure you get updates when they are available.