Over the years I’ve had a few goes at this – for example Running things in parallel using HTML service and Parallel processing in Apps Script, so I’ve decided to do a bigger and better version of those.
Code is on github
Page Content
hide
Quotas
We’ve all come across the problem of the run time limit, trigger timing accuracy, cache size limitations and so on, all of which makes running significantly sized jobs difficult. Splitting the job up into chunks is possible of course, but then bringing all the data back together and storing it somewhere in the meantime is a problem. A large job will also use up so much memory that the Server side JavaScript will run very slowly or not at all.
GasThreader
is my latest solution to these conundrums and has these features
- Run stages in sequence
- Automatically split stages of jobs into manageable chunks that can be run in parallel.
- Watch progress on a webapp dashboard.
- Persist all the results Server side, and have access to any previous stage.
- Automatically reduce the results of parallel chunks.
- Be restartable (not yet, but soon)
This post consists of multiple parts, so if you want to get right to it –
Dashboard
The job is to retrieve almost 1m rows from a Fusion table, analyze and manipulate the data, and optimize sql scripts so it can be imported into a Google Spanner or CockroachDb SQL database. This amount of data is not even loadable into Apps Script in the regular run time limit – in other words I can’t even get to stage 3.
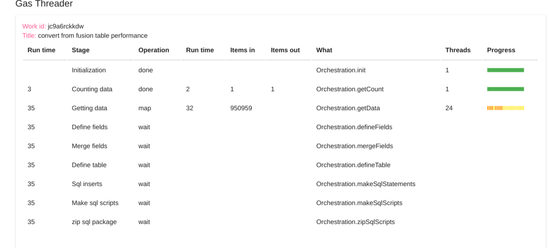
Here’s a couple of screenshots from a large run, in the middle of running, with some notes.
- The Getting data stage has been split into 24 “Threads”, all running the same script “Orchestration.getData”, in parallel.
- The light yellow blobs are threads currently in progress, and the dark yellow are threads that have completed so far.
- “Items in” shows the number of items that need to be processed by each stage, and “Items out” are how many items were created.
- There are implicit split, map and reduce operation associated with each stage
- The data is never passed over to the client (in this case it would be too large anyway), and is persisted Server side using compression and cache record linking (Zipping to make stuff fit in cache or properties service.) to overcome cache quota limits.
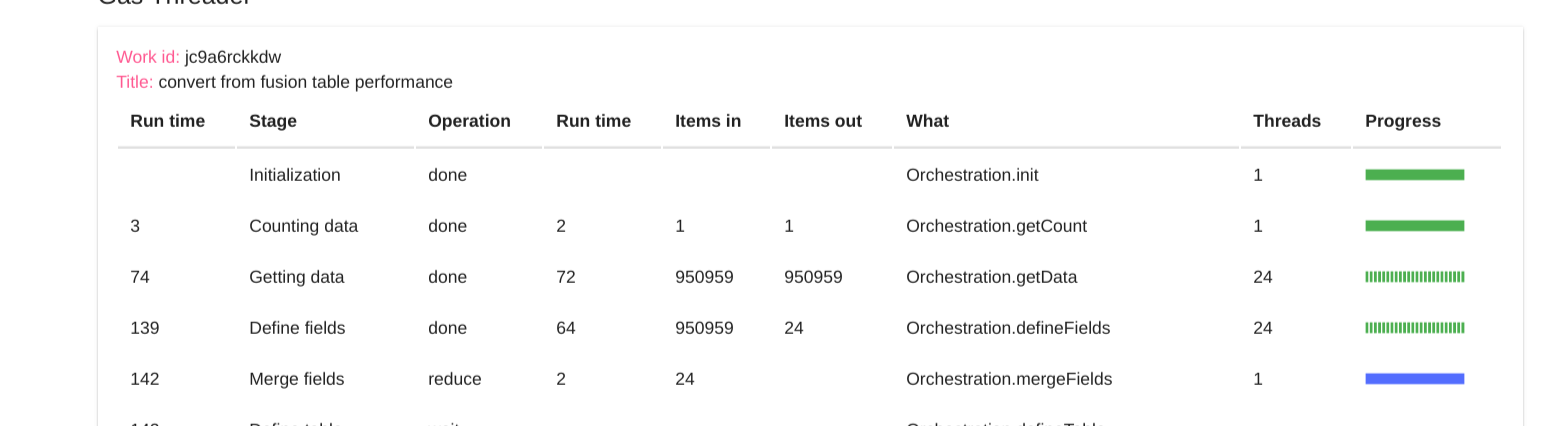
Here we are a little further along, the blue shows a reduce operation in progress
And finally, the job is complete
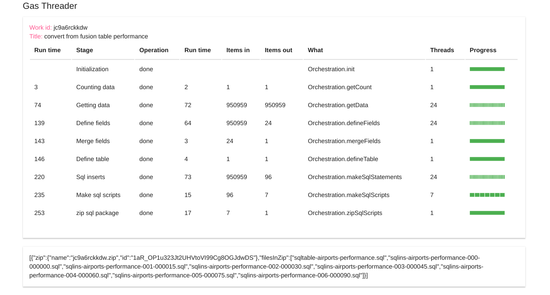
The final output is a zip file containing a set of sql files to optimized to bring this data in to cockroachDB, which I’ll use over on my Getting cockroachdb running on google cloud platform page.
Next
- Jobs, work, stages, threads and chunks
- Namespaces and App structure
- Creating a work package
- The Orchestration namespace
Why not join our forum, follow the blog or follow me on Twitter to ensure you get updates when they are available.