- Orchestration of Apps Scripts – parallel threads and defeating quotas
- Jobs, work, stages, threads and chunks
- Namespaces and App structure
- Creating a work package
Getting started.
// This is called by server to get info on what the work is
ns.init = function () {
// get the work
const work = Job.getJob ("performance");
// keep to this pattern for initalization
return Server.initializeWork (work);
};
Note that your app will look nothing like mine from now on, but all the principles will be covered in each of the following stage descriptions.
Counting stage
The next stage in my App is to go to the Fusion table and see how many rows it contains. Each Orchestrate function receives a standard argument, which looks like this
{
stages
stageIndex
chunkIndex
}
- stages – all the info from the work package, plus calculated thread and chunk information
- stageIndex – the index in the work package
- chunkIndex – the chunk or thread index. If there is no parallelism (maxThreads = 1) , then this will always be 0.
/**
* @param {object} pack (stages, stageIndex, chunkIndex)
* @return {object} updated chunk
*/
ns.getCount = function (pack) {
const stage = pack.stages[pack.stageIndex];
const chunk = stage.chunks[pack.chunkIndex];
const arg = stage.instances.arg;
// do the work - any arguments will be as below
const count = FusionToDB.getCount (arg)[0].count;
// register it for future reference
// normally the count of items will be the length of result, but it can
// be overridden by a number or a function in the 4th argument
return Server.registerChunk (stage, chunk , [count] , arg.maxr ? Math.min(count,arg.maxr) : count );
};
- stage – the stage being processed
(stages[stageIndex]) - chunk – the chunk being processed
(stages[stageIndex].chunks[chunkIndex]) - result – an array of results from this chunk
- optionally a resultCount value – in most cases this can be omitted and the length of the result array will be used. However in this case, there was only one result – a count of the number of rows in a table. I want to signal the next stage that it will have that count number of items to process. This will be used to calculate the optimum number of parallel threads to use to retrieve the data.
![]()
Get data stage
ns.getData = function (pack) {
// get the reduced stage - all the data
const stage = pack.stages[pack.stageIndex];
const chunk = stage.chunks[pack.chunkIndex];
// Important
// if you need to modify arg - clone it first
const arg = Utils.clone(stage.instances.arg);
// in this case there's no data to get,
// as the previous stage was just a count
// arg contains the info needed to open the db
// add the slice I'm doing
arg.maxr = chunk.chunkSize;
arg.start = chunk.start;
// there's other chunking that happens in Fusion too
// as there's a limit to how much can be read in one go
// that's dealt with invisibly here
const result = FusionToDB.getChunked (arg);
// register it for future reference
return Server.registerChunk (stage, chunk, result);
};
chunk.chunkSizechunk.startDo not modify stage.instances.arg – as it is part of the stage object which will be carried forward to the next stages. If you do need to fiddle with arg – as I do in this example for demonstration – clone it first. You can use Utils.clone().
{
stage: "getData",
stageTitle: "Getting data",
skipReduce: true,
// the maximum number of chunks to break the job into omit for the default
maxThreads: 24,
// the min size of a chunk to avoid splitting job into inefficiently small chunks
// omit for default
minChunkSize: 200,
// the
instances: {
namespace: "Orchestration",
method: "getData",
arg: fusion
}
},
Define fields stage
/**
* we have to merge several definitions
* @param {object} pack (stages, stageIndex, chunkIndex)
* @return {object} updated chunk
*/
ns.defineFields = function (pack) {
// get the reduced stage - all the data
const stage = pack.stages[pack.stageIndex];
const chunk = stage.chunks[pack.chunkIndex];
// we're going to enhance this arg, so take a copy
const arg = Utils.clone(stage.instances.arg);
// the results from the previous stage (or I could seeach for its name)
const prev = pack.stages[pack.stageIndex -1];
// normally prev.result would contain the reduced data from the previous stage
// but this takes care of the chunks being different sizes
arg.data = Server.getSlice (prev ,chunk.start , chunk.chunkSize + chunk.start);
// look at all the data and figure out the field types
const result = FusionToDB.defineFields (arg);
// register for this chunk
return Server.registerChunk (stage, chunk, result, 1);
};
- how to get the previous stage
- how to get data from a previous stage – when the reduce operation has been skipped. It may be that the number of threads in this stage is different than the stage from which we’re getting the data, but Server.getSlice takes care of that by scanning across several previous chunks if required.
Merge fields stage
/**
* we have to merge several definitions
* @param {object} pack (stages, stageIndex, chunkIndex)
* @return {object} updated chunk
*/
ns.mergeFields = function (pack) {
// get the reduced stage - all the data
const stage = pack.stages[pack.stageIndex];
const chunk = stage.chunks[pack.chunkIndex];
// the previous stage (or I could seeach for its name)
const prev = pack.stages[pack.stageIndex -1];
// get all the data from the previous stage
const reduced = Server.getReduced (prev);
// merge the fields
const fields = reduced.result.reduce (function (p,c) {
Object.keys(c)
.forEach (function(k) {
if (!p[k]) {
p[k] = c[k];
}
else {
/// merge the field definition
if (c[k].type !== p[k].type) {
// discovered mixed types
if (p[k].type === "INT" && c[k].type === "FLOAT") {
p[k].type = "FLOAT";
}
else {
p[k].type === "STRING";
}
p[k].size = Math.max (p[k].size , c[k].size);
p[k].nulls += c[k].nulls;
}
}
});
return p;
},{});
// write that chunk
return Server.registerChunk (stage, chunk, fields);
};
- how to get the reduced data (all the chunks combined) from the previous stage
const prev = pack.stages[pack.stageIndex -1];
const reduced = Server.getReduced (prev);
Define table stage
/**
* define table
* @param {object} pack (stages, stageIndex, chunkIndex)
* @return {object} updated chunk
*/
ns.defineTable = function (pack) {
// get the reduced stage - all the data
const stages = pack.stages;
const stage = stages[pack.stageIndex];
const chunk = stage.chunks[pack.chunkIndex];
const arg = Utils.clone(stage.instances.arg);
// the previous stage (or I could seeach for its name)
const prev = pack.stages[pack.stageIndex -1];
// get all the data from the previous stage
arg.typeDefs = Server.getReduced (prev).result[0];
// do the work for this stage
const result = FusionToDB.defineTable (arg);
// find the stage that made the data - as that's the input
const dataStage = Server.findStage ("getData" , stages);
// write that chunk - should only be 1 - and set up the data length as input to next stage
return Server.registerChunk (stage, chunk, result, dataStage.resultLength);
};
- how to find a previous stage by name
const dataStage = Server.findStage (“getData” , stages);
SqlInserts stage
/**
* make sql import statement
* @param {object} pack (stages, stageIndex, chunkIndex)
* @return {object} updated chunk
*/
ns.makeSqlStatements = function (pack) {
// get the reduced stage - all the data
const stages = pack.stages;
const stage = stages[pack.stageIndex];
const chunk = stage.chunks[pack.chunkIndex];
// we're going to enhance this arg, so take a copy
const arg = Utils.clone(stage.instances.arg);
// find the stage that made the data - as that's the input
const dataStage = Server.findStage (stage.dataCount , stages);
// get the chunk of data that matches what needs to be processed in this this chunk
arg.data = Server.getSlice (dataStage ,chunk.start , chunk.chunkSize + chunk.start);
// find the type def
const mergeStage = Server.findStage ("mergeFields" , stages);
const mergeReduced = Server.getReduced (mergeStage);
// add typedefs & data to the args
arg.typeDefs = mergeReduced.result[0];
// its possible to skip within the chunk
const files = [];
arg.skip = arg.skip || 0;
// loop around at optimized sql sizes
const stms = [];
do {
var valChunk = FusionToDB.makeValues (arg);
if (valChunk.length) {
// make SQL insertsmake
arg.values = valChunk;
// make SQL inserts
arg.inserts = FusionToDB.makeInserts (arg);
// write to a sequence of inserts
stms.push(FusionToDB.makeInsertSql (arg));
arg.skip += valChunk.length;
}
}
while (valChunk.length);
// write that chunk - and set up the data length as input to next stage
return Server.registerChunk (stage, chunk, stms);
};
- referencing the datacount property to find the input stage. The work package for this stage has dataCount set to getData.
const dataStage = Server.findStage (stage.dataCount , stages);
- using the results of more than one previous stage. This stage needs both the data stage (which was not reduced) and the mergeFields stage (which was).
// find the type def const mergeStage = Server.findStage ("mergeFields" , stages); const mergeReduced = Server.getReduced (mergeStage);
Make SQL scripts
ns.makeSqlScripts = function (pack) {
// get the reduced stage - all the data
const stages = pack.stages;
const stage = stages[pack.stageIndex];
const chunk = stage.chunks[pack.chunkIndex];
// we're going to enhance this arg, so take a copy
const arg = Utils.clone(stage.instances.arg);
// get the prev stage
const prev = stages[stage.stageIndex -1];
arg.sql = Server.getSlice (prev ,chunk.start , chunk.chunkSize + chunk.start);
// filename starts at chunk start + some offset if given
arg.fileNameStart = (arg.fileNameStart || 0 ) + chunk.start ;
arg.fileNameStem = (arg.fileNameStem || ("sqlins-" + arg.db + "-" + arg.table + "-") ) + zeroPad(chunk.chunkIndex,3) + "-";
arg.fileExtension = arg.fileExtension || ".sql";
arg.folderId = arg.folderId || DriveApp.getRootFolder().getId();
var folder = DriveApp.getFolderById(arg.folderId);
if (!folder) throw 'folder for id ' + arg.folderId + ' not found';
const file = folder.createFile(folder.createFile(arg.fileNameStem+zeroPad(arg.fileNameStart,6)+arg.fileExtension, arg.sql.join("\n"), "text/plain"));
// write that chunk
return Server.registerChunk (stage, chunk, file.getId());
};
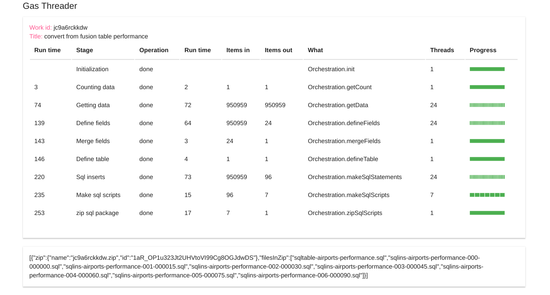
There’s nothing new here, and the stage ends with a Server.registerChunk, and just 7 script files created.
![]()
Zip script files
ns.makeSqlScripts = function (pack) {
// get the reduced stage - all the data
const stages = pack.stages;
const stage = stages[pack.stageIndex];
const chunk = stage.chunks[pack.chunkIndex];
// we're going to enhance this arg, so take a copy
const arg = Utils.clone(stage.instances.arg);
// get the prev stage
const prev = stages[stage.stageIndex -1];
arg.sql = Server.getSlice (prev ,chunk.start , chunk.chunkSize + chunk.start);
// filename starts at chunk start + some offset if given
arg.fileNameStart = (arg.fileNameStart || 0 ) + chunk.start ;
arg.fileNameStem = (arg.fileNameStem || ("sqlins-" + arg.db + "-" + arg.table + "-") ) + zeroPad(chunk.chunkIndex,3) + "-";
arg.fileExtension = arg.fileExtension || ".sql";
arg.folderId = arg.folderId || DriveApp.getRootFolder().getId();
var folder = DriveApp.getFolderById(arg.folderId);
if (!folder) throw 'folder for id ' + arg.folderId + ' not found';
const file = folder.createFile(folder.createFile(arg.fileNameStem+zeroPad(arg.fileNameStart,6)+arg.fileExtension, arg.sql.join("\n"), "text/plain"));
// write that chunk
return Server.registerChunk (stage, chunk, file.getId());
};

This is the only tweaking you need to do to the Client side code (in red below), and I may improve this in future versions.
window.onload = function() {
// set up client app structure
App.initialize();
Home.init();
// get the ui going
Client.init()
.then (function (result) {
// get the final result
return Provoke.run("Server","getReduced",result.stage)
.then (function (reduced) {
Render.showResult (JSON.stringify(reduced.result));
App.toast (result.work.title,"completed");
})
})
['catch'](function(err) {
App.showNotification ("work failed", err);
});
};
Previous
- Orchestration of Apps Scripts – parallel threads and defeating quotas
- Jobs, work, stages, threads and chunks
- Namespaces and App structure
- Creating a work package
Why not join our forum, follow the blog or follow me on Twitter to ensure you get updates when they are available.