I was talking to some cockroachDB developers at an event lately and discovered that many of them were, like me, using ElasticSearch for full text and complex querying in the cases where SQL was not appropriate. One of the topics that came up a lot was the difficulty in keeping the elastic indices up to date with changes that were happening in the database. A database with hundreds of tables and lots of cross-referencing is very difficult to synchronize without simply rebuilding the indices from time to time. In this post, I’m not going to share a lot of code, partly because it’s not public, but mainly because there’s a lot of it that is very specific to my project. Instead, I’ll mainly be discussing the technique to solve the problem
GraphQL
Luckily, I use GraphQL in front of my cockroachDB database, so this abstraction allows the enhancement of mutations to include requests to rebuild the affected index. It’s still pretty complex to figure out what indices a particular change will affect, but the extra abstraction that GraphQL gives is a great advantage, especially if you have a generic function for creating mutations shared by them all. First some background.
Searching
This search for beer returns films which feature beer in some way. I can hover over the reasons for selection and find out why – for example, the highlighted film was selected because it is about the product ‘beer’. Others were selected because the film metadata mentions it, there was someone associated with the film called Beer, it won an award for beer, because an automatic transcription from voice revealed the word beer being mentioned, or even because a video analysis of the film revealed that there was a beer associated image somewhere in the film. That’s a whole bunch of reasons for a film to be selected, all driven from a selection of Elastic Search indices.
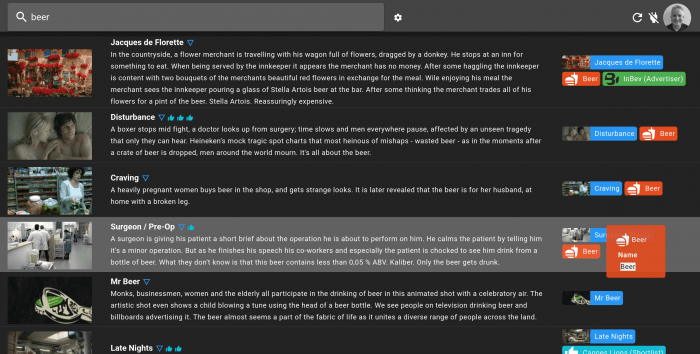
In fact, here’s a selection of some of the reasons that a search might pick up a film. The same kind of selection criteria applies to find people, brands and so on.

So if assigning someone to a film, for example, would modify the film findability, we really need a way to rebuild the film index to take account of that change more quickly than some kind of batch rebuild. What’s more, we also need to rebuild the people index that features that person, along with anything else that person is associated with.
The database
Mutations
// build the values
const sql = `INSERT INTO "${tableName}"${sqlColumnText}${sqlValuesText} RETURNING *;`;
if (verbose) {
// dont show it all
console.log('mutating items', configs.length, sql.slice(0,100), configs.slice(0,20));
}
// log any pool usage info required
return connectAndExecute (
poolClient=>poolClient.query(sql,configs).then(res => res.rows)
)
.then(obs=>{
// this requests any elastic re-indexing
elReindexing({tableName, obs}).then(er=>{
// if re-indexing is required there will be some ids
if (er.ids) {
// we can simply reuse the reindex mutation
// and since the return is the same format as mutation params, they can be passed as is
// the provoke will catch and report any errors so no need to catch here
ns.provokeElReindex ({
params: er
});
}
});
// no need to wait for the pubsub to be issued as it wont be executed right away anyway
return obs;
})
.catch(err =>
errors.gqlError(err, 'failed to create item(s) in DB', errors.codes.DB)
);
The piece of interest here is the elReindexing function. Given a tableName and the result of a mutation its purpose is to figure out if any Elastic indices need rebuilding, and if so which ones and which document ids are affected.
Reindexing
The reindexing function itself is provoked – it doesn’t run as part of the GraphQL API request which needs to be getting its update response back as soon as possible. Instead, it publishes a pubsub message, which in turn wakes up a Google Cloud Run function that does the selected reindexing.
Exactly what needs to be reindexed is driven by a definition file that is related to the ElasticSearch mappings. Here’s a snippet for what happens if a given brand document needs to be updated. From this, I can know that in addition to the brand document index, I also need to reindex the product, company and film indices.
brand: [{
type: 'brand',
idField: 'id',
gQuery: 'riBrands',
gPluck: 'brandID',
} , {
type: 'product',
idField: 'ProductToBrands.brandID',
gPluck: 'BrandToProducts.productID'
} ,
{
type: 'company',
idField: 'CompanyToBrands.brandID',
gPluck: 'BrandToCompanies.companyID'
}, {
type: 'film',
idField: 'FilmToBrands.brandID',
gPluck: 'BrandToFilms.filmID'
} ],
However, we want to selectively update those indices – only those documents directly related to the original brand update. There are 2 parts.
Identify all elastic documents in any index (identified by the type property) that refer to the brandID being updated and remove them. The idField points to the Elastic mapping path at which they can be found
- Find all data in the database related to the brand just updated. The gQuery property refers to a graphQL query to find them and the gPluck fields describe how to pull out their ids. These documents will be re-indexed
In principle, these 2 lists of ids should be the same, but it’s possible that the elastic documents being deleted might not exactly match the current state of the database. Here’s a snip of the code to do this.
return Promise.all (queries.map(f=>elclient.getDocIds({index:f.index,body:{...f.query,size:maxSize}})))
.then(r=>{
// make sure we got them all - if there are more matches than maxsize, this will fail
r.forEach(f=>{
if (f.hits.length !== f.total.value) {
throw new Error(`....hits ${f.hits.length} dont match total ${f.total.value} - rebuild the whole thing`);
}
});
// we can concatenate the hits and remove dups too
const hits = [].concat(...r.map(f=>f.hits))
.filter((f,i,a)=>a.findIndex(g=>g.id===f.id && g.index === f.index) === i);
// and turn it all into a single bulk request
console.log('....bulk deleting ', hits.length, 'items', hits);
const body = hits.flatMap(doc => [ {"delete":{"_id":doc.id, "_index":doc.index}}]);
// these are the rebuild tasks after deletion
// an object where each property is an index, that contains the list of ids to rebuild
// because they were found in the document that needs to be deleted
const deleteTasks = hits.reduce((p,c)=>{
if (!p){
p = {
index: c.index,
ids: []
};
}
// turn doc id (type-id-n) into a gql ID - just id
p.ids.push(c.id.replace(/.*?-(\d+).*/,"$1"));
return p;
},{});
// we also need to search GQL for hits on the targets being deleted, because
// the EL index might not be exactly in step so the el docs are the source of truth for
// what gets deleted, and gql is the source for what needs rebuilt
// these lists are merged and define the docs that need rebuilding
const mob = targets.find(f=>f.type === type);
if (!mob || !mob.gQuery) {
throw `couldnt find gQuery - add its name to the reindex map for type ${type}`;
}
// kick that off
console.log('....starting db check for matches');
const gqPromise = getAllChunks ({
...load,
query: mob.gQuery,
partial: true,
maxItems: ids.length + 2,
filters: [{
valueKey: gidField,
value: ids
}]
});
// and also the elastic index deletes
console.log('....starting deletes');
const bulkDeletes = body.length ? elclient.bulk({
body,
refresh: true
}) : Promise.resolve(null);
// when both are done we can get on with the rebuild
return Promise.all([
bulkDeletes.then(()=>deleteTasks),
gqPromise.then(r=>{
return targets.map(f=>{
const d = pluckey(r.data,f.gPluck);
return d && d.length && d[0] ? {
index: f.index,
ids: d
}: null;
})
.filter(f=>f)
.reduce((p,c)=>{
if(p) {
throw new Error('unexpected index dup ' + c.index);
}
p = c;
return p;
},{});
})
]).then (r=>{
const [e,g] = r;
// now we have the results from both the deletions and the gql search
// combine and dedup
const combined = targets.reduce((p,c)=> {
const lids = [];
// add them together
if (e && e) Array.prototype.push.apply(lids,e.ids);
if (g && g) Array.prototype.push.apply(lids,g.ids);
// dedup
if (lids.length) {
p.push({
ids: lids.filter((f,i,a)=>a.indexOf(f) === i),
index: c.index
});
}
return p;
},[]);
// now the rebuilding
console.log('....starting rebuiding');
return Promise.all(combined.map(f=>{
// find the matching task definition
const mob = targets.find(g=>g.index === f.index);
if (!mob) {
throw new Error('couldnt find target for ' + f.index);
}
return {
...load,
filters: [{
valueKey: gidField,
value: f.ids
}],
indexName: mob.index,
idField: gidField,
mappings: mob.mappings,
settings: mob.settings,
query: mob.query,
partial: true,
maxItems: f.ids.length + 2,
};
}).map(f=>{
return chunkyBuild(f);
}));
});
});
I won’t go into the details of the helper functions as they are specific to this project, but in summary
- getDocIds gets the document ids of elastic documents that match elastic queries built from the mapping reference file. These are combined into a bulk delete.
- chunkBuild executes graphQL queries to get related items from the database, again built from the same mapping reference file, then to rebuild the affected indices.
Log file
Here’s what happens during a trial local run of a request to update brand id ‘1’. Notice it detected that other documents in other indices needed to be rebuilt too.
....bulk deleting 11 items [
{ id: 'Brand-1-0', index: 'fidsearcherbrand' },
{ id: 'Product-1-0', index: 'fidsearcherproduct' },
{ id: 'Product-274-0', index: 'fidsearcherproduct' },
{ id: 'Company-2435-0', index: 'fidsearchercompany' },
{ id: 'Film-29-0', index: 'fidsearcherfilm' },
{ id: 'Film-238-0', index: 'fidsearcherfilm' },
{ id: 'Film-444-0', index: 'fidsearcherfilm' },
{ id: 'Film-600-0', index: 'fidsearcherfilm' },
{ id: 'Film-621-0', index: 'fidsearcherfilm' },
{ id: 'Film-860-0', index: 'fidsearcherfilm' },
{ id: 'Film-934-0', index: 'fidsearcherfilm' }
]
....starting db check for matches
....starting gql query chunks riBrands maxItems 3
....starting deletes
....finishing gql query riBrands items 1 took 990
....starting rebuiding
....getting fidsearcherbrand offset 0 maxItems 3
....getting fidsearcherproduct offset 0 maxItems 4
....getting fidsearchercompany offset 0 maxItems 3
....getting fidsearcherfilm offset 0 maxItems 9
....graphql done for fidsearchercompany at offset 0 limit 3 took 789 ms
....graphql done for fidsearcherbrand at offset 0 limit 3 took 883 ms
....graphql done for fidsearcherproduct at offset 0 limit 4 took 1062 ms
....graphql done for fidsearcherfilm at offset 0 limit 9 took 1080 ms
....elastic written to fidsearcherbrand 1 took 890 ms roundtrip 1083 ms
Finishing elastic load of fidsearcherbrand 1 items
....elastic written to fidsearcherproduct 2 took 963 ms roundtrip 1086 ms
Finishing elastic load of fidsearcherproduct 2 items
....elastic written to fidsearchercompany 1 took 1544 ms roundtrip 1761 ms
Finishing elastic load of fidsearchercompany 1 items
....elastic written to fidsearcherfilm 7 took 1215 ms roundtrip 1442 ms
Finishing elastic load of fidsearcherfilm 7 items
Back to the mutation
The exact same reference file can be used to identify what needs to happen when a given table is updated. Since the table names are constructed in a standard way, it’s possible to deduce an affected table and link table name, and thus whether or not any re-indexing is required. For example, if a mutation involves the brandToFilm table a simple search of the mapping defintion file will reveal whether that provokes an update, and the same definition will reveal where to the find the id of the document that needs to be redone. The reindexing task has the responsibility of discovering everything else affected so there’s no need to worry about that in the API. Like this
/**
*
* @param {string} tableName the table thats been affected
* @param {[object]} obs the result of the update
* @return {object} the ids and type for input to elreindex
*/
const elReindexing = ({tableName, obs}) => {
const relMap = ns.relMap[tableName];
// the idea is to review which fields are interesting fr re-indexing
// by referencing the definition that does the indexing
// because the indexing processing itself finds everything related
// all we have to do is find it once
return new Promise ((resolve, reject) => {
// if this is mappable we have to find the ids of the type thats changing
const ids = !relMap ? null :
// now we have to extract the id from the result of the mutation
// skip null obs if there are any, and then skip any missing ids
obs.filter(f=>f).map(f=>{
const id = f[relMap.idField];
if (!id) {
console.log (`warning - missing idfield value ${relMap.idField} in ${JSON.stringify(f)}`);
} else {
return id;
}
}).filter(f=>f);
// this instructs which type needs rebuilt and which ids it applies to
resolve ({
obs,
ids: ids && ids.length && ids,
...relMap
});
});
};
Provoke reindex
The mutation provokes a pubsub message so that cloud run can get on and do the work.
ns.provokeElReindex = rgs => {
const {params} = rgs;
// ids are the ids of the items that need to be rebuilt
// type is something like 'person'
let {ids, type} = params;
if(ids && !Array.isArray(ids)) ids =[ids];
// this will define which subscription gets the message
const mode = getFidRunMode();
// these are the same args that are supplied to elastic/bulkcli and bulkcloud
const bargs = {
type
};
// no ids builds the whole index
if(ids && ids.length) bargs.ids = ids;
// pubish a pubsub request for this to be run (on cloud run)
return elps.publish({
ob: {
mode,
bargs,
workType: 'elb'
},
type: 'elb',
})
.then (r=> ({
messageID: r.toString(),
timeStamp: new Date(),
ids,
type
}))
.catch(err=> {
errors.gqlError(err, `failed to publish reindex for ${type}`, errors.codes.DB);
});
};
This is actually a mutation resolver being reused – the makes it even possible to provoke a rebuild through GraphIQL if you need some repairs or custom rebuilding.

Summary
For as long as you keep table names standard (mine almost are, but they needed a little tweaking with minor upper and lower camel case issues), all indices will automatically be kept up to date. The API does a one-off preparation to fix those issues and make a faster lookup for my mapping definition file.
ns.relMap = Object.keys(reindexMap).reduce((p,c)=> {
const bob = reindexMap;
bob.forEach (f=>{
// we can get the tablename from the gpluck field initially
const {gPluck, type} = f;
const plucked = gPluck.split('.');
// default - would apply if this is a main table
const rob = {
type,
tableName: c,
idField: gidField
};
// this would apply if its a link table
if (plucked.length === 2) {
// link tables are for example filmToCompany
// so the current main type + To + the current subtype
rob.tableName = `${c}To${type.slice(0,1).toUpperCase()}${type.slice(1)}`;
rob.idField = plucked[1];
} else if(plucked.length !== 1) {
// can only handle 1 deep for now - TODO if reindexmap becaomes more complicated, this will need improved
throw new Error('can only expect 1 deep on reindexmap plucked idfield');
}
// index this by table name to find it quickly
if (!p[rob.tableName]) {
p[rob.tableName] = rob;
}
});
return p;
} ,{});
ElasticSearch, Google Cloud Run, Pubsub and GraphQL make a great team!