Before getting started on how to set up Orchestration of Apps Scripts – parallel threads and defeating quotas let’s get a few definitions clarified.
Code is on github
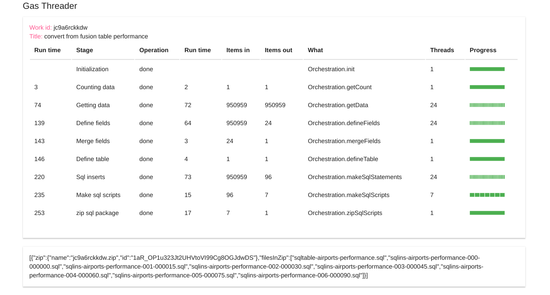
This dashboard will provide the reference point for each of the following sections.
Work
A work package defines the stages, their sequencing and how to split up the work in each stage. Each instance of a work package gets a unique ID which is used to associate the data from stage with its work package. The dashboard above shows an instance of a completed work package consisting of 9 stages, with a unique ID. assigned.
Job
Often a work package can be re-used, but with different parameters. Making it generic means you can create these work packages more quickly and accurately. I often refer to a Job as parameters provided to a Work Package to customize its behavior – for example passing different spreadsheet IDS and so on.
Stage
A stage is some work that must be completed before the next stage can start, and it begins with a split operation. The number of items to be processed in a stage, along with the maximum number of threads and the minimum chunk of data size is used to work out how many threads can be run in parallel. This split stage also calculates the start and length of the number of items that are to be processed by each thread of the stage. A stage will normally end with an automatic reduce operation to bring together all the results of each of the threads, but there are exceptions which will be covered later.
Thread
A thread in an instance of a call to a single server side script. If sections of work can be run in parallel, creating multiple threads is a great way to get lots of work done at the same time. The dashboard represents each thread as a separate rectangle which can be either
- yellow – mapping in progress
- amber – mapping complete
- blue – reduce in progress
- red – failure
- green – complete
Chunk
A chunk of data is worked on by a thread – there will be exactly 1 thread for 1 chunk – so the number of chunks in a stage will equal the number of threads. A chunk of data is mapped (transformed) by a thread. The number of items in to a chunk doesn’t need to equal the items in – you can do any kind of transformation – but you cannot interact with any other chunk of data in the same stage as it will be running at the same time.
Items in/out
Normally a stage process the result of the previous stage, although you can access the data from any previous stage or work on data from multiple stages if required. The number of items in is the total number of items created by reducing (combining) the data created by the previous stage (its Items out).
Reduce
A reduce operation will combine each of the chunks created by each thread into a single result, and happens automatically at the end of each stage. This makes the complete result easily available to future stages. However, since you make be dealing with vast amounts of data, combining them and accessing them later may take too much memory to be viable or efficient. It is possible to skip the reduce stage, and access the chunks directly later. Functions are provided to be able to access data which spans multiple chunks, so for bigger data sets its often preferable to skip the reduce operation all together. Even when you skip a full reduce operation, there is still a “virtual” reduce operation to do some end of stage tidy up .
Why not join our forum, follow the blog or follow me on Twitter to ensure you get updates when they are available.