Coding a connector for Data Studio (without using data studio)
This series of articles will work through how to create a connector for Data Studio in Apps Script. For an introduction into the structure I’ll be following see Creating a connector for Data Studio
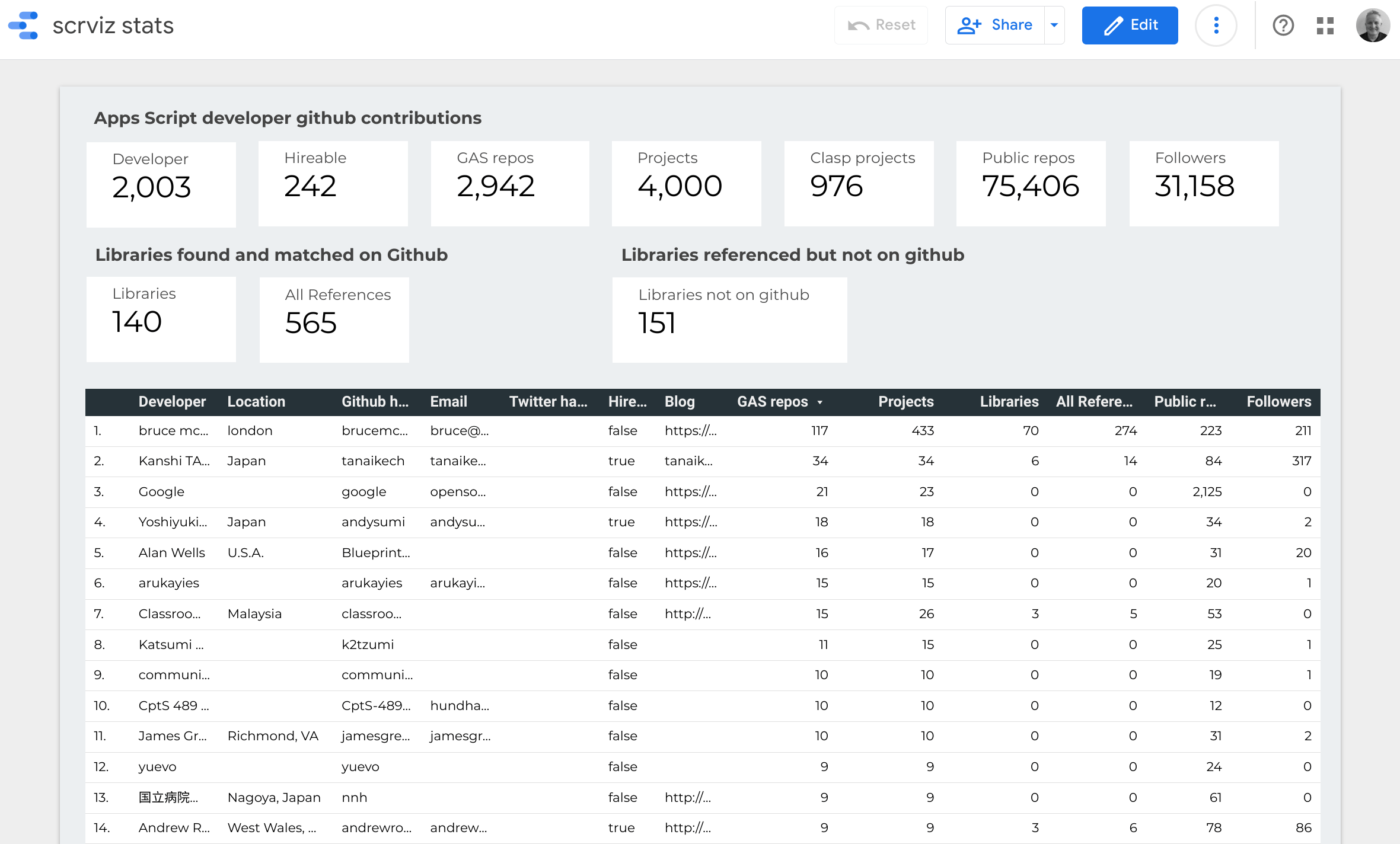
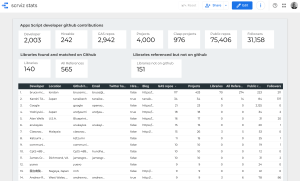
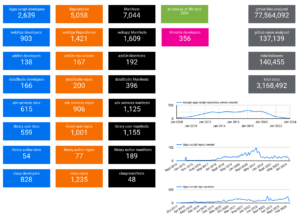
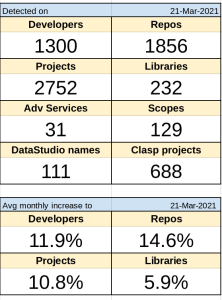
This article will go through coding up the functions required to feed Data Studio, but we won’t actually connect to Data Studio till a later article. The source data will be the github apps script project catalog from Every Google Apps Script project on Github visualized. We’ll be using the Apps Script library that knows how to get the data from Apps Script projects on github. The live scrviz app can be found here. Creating a Data Studio connector will allow a more detailed , customizable analysis of the 4000+ projects scrviz has cataloged.
What I’m after initially is a simple Data Studio report by owner on the scrviz data, like this, but first we’ll code up the connector and get it working as an Apps Script library.
Project layout
Starting with the main namespaces, and exporting the mandatory functions that’ll be needed by Data Studio, which will be implemented in the Connector namespace. I’ll build up the detail of this code as we go through the article.
// generic test to see if we're allowed to use cache const _cacheService = CacheService.getScriptCache();
// This namespace is all about getting and formatting data const dataManip = (() => { //.... })();
// this namespace defines and exports all the required methods for a datastudio connector var Connector = (() => { //..... })();
// export these globally so that datastidio can see them var getConfig = () => Connector.getConfig(), isAdminUser = () => Connector.isAdminUser(), getSchema = () => Connector.getSchema(), getAuthType = () => Connector.getAuthType(), getData = (request) => Connector.getData(request), getVizzy = () => Connector.getVizzy()
basic structure of main code file
We’ll also need some code to reduce the data coming from the scrviz API to rows at the level required for my Data Studio report.
const flattenVizzyOwners = (data) => { //.... }
reduce to owner level
And finally, since we’re supporting caching using the Apps Script CacheService, we’ll need a way of compressing the data and spreading it over multiple cache entries, as it’ll be bigger than the allowed amount.
var Digestive = (() => {
})()
handling cache
Why sometimes var and sometime const?
Since this will be a library, some functions might need to be exposed from the library, whereas others are purely local. Apps Script has no module support, so we need to use var for exposable functions (var declarations are still ‘hoisted’ in V8, which will guarantee they’ll be visible in the correct order via the library), and const for locally accessed functions.
Why structure like this?
The next time I create a Data Studio connector, much of this code can be reused with just field names changed, and even the dataManip namespace will remain the same shape, but with the details of data access and manipulation tailored for the specific data source. So what I’m after is a template that can be used by me (and possibly others) to plug in to the next time. That’s the intention in any case – I’ll let you know if it worked when I create my next connector.
Connector namespace
This contains the data specific details for the connector and implements the madatory functions required for Data Studio. This namespace should be reusable between connectors with only minimal changes.
Connector local variables and functions
To generalize the Connector namespace, I’m importing various functions from the specific dataManip namespace that are specific to this project (and will probably be the same for other similar projects).
I’ve implemented various levels of caching in this connector, as the source data set is pretty big – so if we can avoid reprocessing, it’s going to help. Also there’s a pretty strict rate limit on unauthenticated github access so I need to minimize how many times we hit that API. These user parameters will allow modification of caching behavior for unusual circumstances
config .newCheckbox() .setId('noCacheStudio') .setName('disable formatted data caching') .setHelpText('Data may already be available from recently run report')
config .newCheckbox() .setId('noCache') .setName('disable catalog caching') .setHelpText('Data may be available from recently used scrviz access')
return config.build(); };
getConfig
Connector.getFields
These are all the fields I’m planning to present from this connector.
const getFields = () => { var fields = cc.getFields(); var types = cc.FieldType; var aggregations = cc.AggregationType;
This function will be called by datastudio to get the rows of data populated with the fields mentioned in getFields
const getData = (request) => {
// whether to cache is passed in the request from datastudio const c = _fromCacheStudio(request) && cacheStudioGetter(request) if (c) { console.log('Studio data was from cache ', new Date().getTime() - c.timestamp) return c.data }
// need to calculate it all const requestedFields = getFields().forIds( request.fields.map(field => { return field.name }) );
try { const schema = requestedFields.build() const data = fetchIt(request, requestedFields, schema); const response = { schema, rows: data, }; cacheStudioSetter(response, request) return response } catch (e) { console.log(e) cc.newUserError() .setDebugText("Error fetching data from API. Exception details: " e) .setText( "The connector has encountered an unrecoverable error. Please try again later, or file an issue if this error persists." ) .throwException(); } };
getData
Connector exports
These functions are all exposed to pass on via the connector. They’re not all required by the Connector, but may be useful when it’s being used as a library.
// these are called by datastudio return { // https://developers.google.com/datastudio/connector/reference#getdata getData,
This contains code that specific to this API and specific to converting it into a format usable by datastudio. I just reproduce the entire namespace here, but won’t go into the detail as by definition it’s specific to this dataset. However it might provide some guidance on how to format data for use by getData() and on using the caching algorithms in the Digestive namespace. Much of this will be reusable, with only API access and specific data wrangling and formatting needing attention.
// This namespace is all about getting and formatting data const dataManip = (() => {
// we should cache as there will be lots of accesses when setting up datastudio report // and scrviz doesn't run very often
/** * try to sort out the libraries */ const sortOutLibraries = (data) => {
// we need to optimize mapping shaxs to files to do this only once const msf = new Map (data.shaxs.map(f=>[ f.fields.sha, data.files.filter(g=>f.fields.sha === g.fields.sha) ]))
// we also need to know which shaxs have lib dependencies multiple times const s = new Map (data.shaxs.map(f=>[ f.fields.sha, f.fields.content && f.fields.content.dependencies && f.fields.content.dependencies.libraries && f.fields.content.dependencies.libraries.map(g=> g.libraryId) ]).filter(([k,v])=>v && v.length))
// ssf is a map shaxs which reference a given libraryID const ssf = Array.from(s).reduce((p,[k,v])=> { v.forEach(g=>{ if(!p.has(g)) p.set(g,[]) p.get(g).push(k) }) return p }, new Map())
// special clues from those with multiple projects in a repo const mReps = data.repos.map(g=>({ repo: g, multiples:data.files.filter(h=>h.fields.repositoryId === g.fields.id).map(h=> ({ repo: h, projectName: h.fields.path .replace('src/appscript.json','appsscript.json') .replace('dist/appscript.json','appsscript.json') .replace(/.*\/(.*)\/appsscript.json$/,"$1") })) })).filter(g=>g.multiples.length>1)
// now we look at all the known libraries // libraries only have an id a list of versions in use, and a label // we have to try to see if we somehow match then up to known files // however we don't have a scriptID for each file return data.libraries.sort(_compare)
/** * gets the stats from the scrviz repo */ const getVizzy = (request) => {
// whether to cache is passed in the request from datastudio const c = _fromCache(request) && cacheGetter()
if (c) { console.log('Scrviz data was from cache ', new Date().getTime() - c.timestamp) return c.data } else { const { gd, mf } = bmVizzyCache.VizzyCache.fetch(UrlFetchApp.fetch) const data = ITEMS.reduce((p, c) => { p = gd.items(c) return p }, {})
MANIFEST_ITEMS.reduce((p, c) => { if (mf._maps) p = Array.from(mf._maps.values()) return p }, data)
// now let's see if we can find the libraries referred to data.libraries = (data.libraries && sortOutLibraries(data)) || [] cacheSetter(data) return data } }
/** * Formats a single row of data into the required format. * * @param {Object} requestedFields Fields requested in the getData request. * @param {Object} item * @returns {Object} Contains values for requested fields in predefined format. */ const formatData = (requestedFields, item, schema) => {
var row = requestedFields.asArray().map((requestedField, i) => { const v = item[requestedField.getId()]
// no formatting required, except to clean up nulls/udefined in boolean values switch (schema[i].dataType) { case "BOOLEAN": return Boolean(v) case "STRING": return v === null || typeof v === typeof undefined ? '' : v.toString() default: return v } }) return { values: row }; };
return { /** * fetchit just combines the gettinf and formatting of datastudio response */ fetchIt: (request, requestedFields, schema) => { const apiResponse = fetchDataFromApi(request); const normalizedResponse = normalizeResponse(apiResponse); return getFormattedData(normalizedResponse.result, requestedFields, schema); }, getVizzy, cacheStudioSetter, cacheStudioGetter }; })();
dataManip namespace
FlattenVizzy namespace
I’ve kept this separate from the dataManip namespace because it’s about reducing the formatted data to a particular level – in this case aggregation by owner. If I add other aggregations, then this is the only change that’s needed other than to specify the fields for the schema. This namespace is specific to the data source and the level at which it will be consumed.
I’ve written about getting more out of cache services elsewhere. This is an implementation using the Apps Script cache service, along with zip to compress the data, and various techniques to circumvent the size limit on Cacheservice items. This namespace should be reusable with little or no changes.
const digest = (...args) => { // conver args to an array and digest them const t = args.concat([DIGEST_PREFIX]).map(d => { return (Object(d) === d) ? JSON.stringify(d) : (typeof d === typeof undefined ? 'undefined' : d.toString()); }).join("-")
const s = Utilities.computeDigest(Utilities.DigestAlgorithm.SHA_1, t, Utilities.Charset.UTF_8) return Utilities.base64EncodeWebSafe(s) };
/** * zip some content - for this use case - it's for cache, we're expecting string input/output * @param {string} crushThis the thing to be crushed * @raturns {string} the zipped contents as base64 */ const crush = (crushThis) => { return Utilities.base64Encode(Utilities.zip([Utilities.newBlob(crushThis)]).getBytes()); }
/** * unzip some content - for this use case - it's for cache, we're expecting string input/output * @param {string} crushed the thing to be uncrushed - this will be base64 string * @raturns {string} the unzipped and decoded contents */ const uncrush = (crushed) => { return Utilities.unzip(Utilities.newBlob(Utilities.base64Decode(crushed), 'application/zip'))[0].getDataAsString(); }
/** * gets and reconstitues cache from a series of compressed entries */ const cacheGetHandler = (cacheService, ...args) => { // call the cache get function and make the keys const d = digest.apply(null, args) const h = cacheService.get(d) if (!h) return null; const header = JSON.parse(h)
// we have to reconstitute all the entries const str = header.subs.reduce((p, c) => { const e = cacheService.get(c) // and entry has disappeared, so give up if (!e) return null return p e }, '')
const chunker = (str, len) => { const chunks = []; let i = 0 const n = str.length; while (i < n) { chunks.push(str.slice(i, i = len)); } return chunks; }
/** * this will not only compress, but also spread result across multiple cache entries */ const cacheSetHandler = (cacheService,...args) => { const [data, expiry, ...keys] = args const d = digest.apply(null, keys) const strif = JSON.stringify(data) const crushed = crush(strif) const subs = chunker(crushed, MAX_CACHE_SIZE).map((f, i) => { const key = digest(d, i) cacheService.put(key, f, expiry) return key })
const pack = { timestamp: new Date().getTime(), digest, subs } // always want the header to expire before the trailers cacheService.put(d, JSON.stringify(pack), Math.max(0, expiry - 1)) return pack } return { cacheGetHandler, cacheSetHandler } })()
Digestive namespace
Exposing required functions
Finally we need to expose and hoist some functions from the Connector namespace
// export these globally so that datastidio can see them var getConfig = () => Connector.getConfig(), isAdminUser = () => Connector.isAdminUser(), getSchema = () => Connector.getSchema(), getAuthType = () => Connector.getAuthType(), getData = (request) => Connector.getData(request), getVizzy = () => Connector.getVizzy()
exposing connector functions
Testing
I find the simplest way to test the connector is to use it as a library from another script that creates a spreadsheet from the data served up from getData(). For examples of this see Creating a connector for Data Studio
What’s next
This article was an introduction to the coding of a Connector. Next we’ll go through plugging it in to Data Studio
Motivation Every Google Apps Script project on Github visualized describes how to use https://scrviz.web.app to find and visualize public Apps Script ...
bruce mcpherson is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. Based on a work at http://www.mcpher.com. Permissions beyond the scope of this license may be available at code use guidelines