The Video Intelligence API allows you to analyze the content of videos. For my use case this is super useful, because now I can
- Label videos with their content, and use those labels to navigate to the points in the video they appear
- Detect scene changes, and navigate or jump to each scene in a video
- OCR text discovered in a video. For TV advertisments, this helps to identify the produce being advertised
- Get labels for each segment in the video, to identify the general content of the video
- There are other capabilitities such as object and logo detection, as well as transcription, which I may use in the future.
- Deduplication of alternate cuts or formats of the same the film
- Identification of films with similar content
Modes of analysis
You can analyze content either by loading the content to cloud storage (I cover that in More cloud streaming) or by analyzing content real time (streaming video intelligence). The Streaming video intelligence is a little newer, and doesn’t have quite the depth of capabilities as the analysis on a file in cloud storage. It also produces less result depth, so I’m sticking with the regular variant.
The UI
For this example, I’m using an ad from the Guardian, publicly available here.
Here’s the result of the analyzed video in the UI of my app.
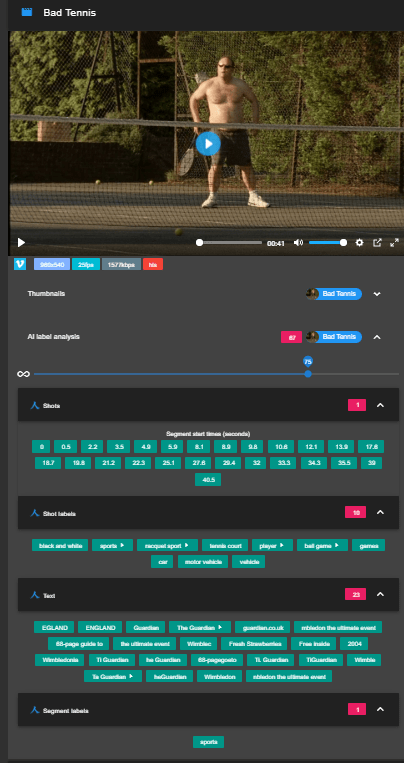
Clicking on any label to takes you to that point in the video.
How is it done
The workflow is
- If there are no labels already available. The user chooses to analyze a film. The UI sets off a graphQL mutation, and the GraphQL API publishes a pubsub message. It’s a longish running task so it can’t really be done interactively.
- A process running in my Kubernetes cluster subscribes to the message and kicks off a process that finds the best known quality version of the film (you get more labels with higher confidence with a goof quality copy), uploads it to cloud storage, runs it through video intelligence and mutates the result via the GraphQL API.
- In the meantime the UI is watching the progress of the workflow via a GraphQL subscription and keeps the user updated on where it’s up to.
- Eventually the labels are available to the UI.
- Once analyzed they are available for all future accesses.
Doing the labelling
This is the entire process from receiving a message, but I’m only going to cover the labelling part in this article. I’ll cover the rest in other articles.
ps.onMessage( async message => {
const { data: pack } = message;
console.debug('received message', message.id);
if (!pack) {
message.consumed();
return reportError('no Pub/Sub message data');
}
pack.id = message.id;
const { workType } = pack;
if (workType !== 'start') {
message.consumed();
return reportError('worktype ' + workType + ' is unknown - skipping');
}
if (pack.mode !== mode) {
message.consumed();
return reportError('invalid mode'+ pack.mode + ' expected ' + mode);
}
console.debug('working on ', workType, pack.mode, pack.filmMasterID);
// now do the work .. previous this was a pubsub message but now doing it all in one process
// start off and do the apolloo query
const orch = await labelOrchestrate.start({ pack });
let stage = await finishCleanly({ workType: pack.workType, pack, result: { ...orch, workType: 'upload', mode: pack.mode }});
if (stage.failed) return;
// upload the file to gcs
const upload = await labelOrchestrate.upload({ pack: stage });
stage = await finishCleanly({ workType: stage.workType, pack, result: { ...upload, workType: 'label', mode: pack.mode }});
if (stage.failed) return;
// do the labelling
const annotate = await labelOrchestrate.annotate({ pack: stage });
stage = await finishCleanly({ workType: stage.workType, pack, result: { ...annotate, workType: 'vilabel', mode: pack.mode }});
// update the db
const vil = await labelOrchestrate.viLabel({ pack: stage });
stage = await finishCleanly({ workType: stage.workType, pack, result: { ...vil, workType: 'done', mode: pack.mode } });
// finally
stage = await finishCleanly({ workType: stage.workType, pack, result: stage });
message.consumed();
});
There’s a couple of wrappers to make the results from each stage consistent. The secrets object contains a GCP service account that has credentials authorized to run the video intelligence API and access cloud storage.
const annotate = async ({ pack }) => {
console.debug('..started annotation');
const annotated = await doAnnotate ({ pack });
return annotated;
};
const doAnnotate = async ({ pack }) => {
const startedAt = new Date().getTime();
const { workType, filmMasterID } = pack;
console.debug('..starting annotation', filmMasterID);
const content = await labelAnnotate.annotate({ content: pack });
if(content.error) {
return content ;
}
// now return content
return {
...content,
annotationPhase: {
startedAt,
elapsed: new Date().getTime() - startedAt,
attempts: 1 + ((pack && pack.annotationPhase && pack.annotationPhase.attempts) || 0)
}
};
};
// does video analysis
const vint = require('./vint');
const secrets = require('./private/visecrets');
const storageStream = require('./storagestream');
const till = (waitingFor) =>
waitingFor.then(result => ({result})).catch(error => ({error}));
const annotate = async ({ content }) => {
vint.init(secrets.getGcpCreds({ mode: content.mode }));
// this is the workorder to kick things off
const result = await vint.processVideo({
description: content.filmName,
videoFile: content.uploadVideoFile
});
// write to storage
content.shotLabelsCount = result.shotLabels.length;
content.shotSegmentsCount = result.shotSegments.length;
content.segmentLabelsCount = result.segmentLabels.length;
content.textSegmentsCount = result.textSegments.length;
content.labelsResults = `${secrets.getGcpCreds({ mode: content.mode }).labelsFolder}/labels_${content.uploadVideoFile.replace(/.*\//,'')}.json`;
const { error: sError, result: sResult } = await till(
storageStream.streamContent({
content: {
...content,
...result
},
name: content.labelsResults,
mode: content.mode
}));
if (sError) {
content.error = sError;
}
return content;
};
module.exports = {
annotate
};
The labelling
You can do a number of feature detection in the same run. Here I’m doing shot changes, labels and text detection. A couple of points of interest are.
- The segment object is pretty standard for each result type, and consists of a start offset an end offset and a confidence value.
- This is a ‘google long running operation’ which has a pretty funky interface to get the result. See here for my write up on it, and below for it in action
And that’s about it. Just pass the uri on cloud storage, tell it the features required, unravel the rather complex responses and you’re done.
module.exports = (() => {
let viClient = null;
let viBucket = null;
const fs = require('fs');
const video = require('@google-cloud/video-intelligence').v1p3beta1;
const util = require('util');
const till = (waitingFor) =>
waitingFor.then(result => ({result})).catch(error => ({error}));
// various configurations for different kinds of analysis
const configs = {
all: {
features: [
'SHOT_CHANGE_DETECTION',
'LABEL_DETECTION',
'TEXT_DETECTION'
]
}
};
const getTimeOffset = (timeOffset) => {
const { seconds, nanos } = timeOffset;
return parseInt(seconds || 0, 10) + parseInt(nanos || 0)/1e9;
};
// initialize service creds
const init = (gcpCreds) => {
viClient = new video.VideoIntelligenceServiceClient({
credentials: gcpCreds.credentials
});
viBucket = gcpCreds.bucketName;
};
// manage a long running annotation operation
const doLong = async (request) => {
// its a long running operation
const { result, error } = await till(viClient.annotateVideo(request));
const [operation] = result;
// console.debug ('annotating', request, { error } );
// when done, retrieve the result
const { result: oResult, error: oError } = await till(operation.promise());
const [operationResult] = oResult;
// console.debug('getting result', { oError });
return operationResult;
};
const makeTextPack = ({ items }) => items.map(label => ({
description: label.text,
segments: makeSegments({ segments: label.segments })
})).filter(f => f.segments.length);
const makePack = ({ items }) => items.map(label => ({
description: label.entity.description,
categories: (label.categoryEntities || []).map(f => f.description),
segments: makeSegments({ segments: label.segments })
})).filter(f => f.segments.length);
const makeSegments = ({ segments }) => segments.map(segment => {
const { startTimeOffset, endTimeOffset } = segment.hasOwnProperty('segment') ? segment.segment : segment;
const result = {
startTime: getTimeOffset(startTimeOffset),
endTime: getTimeOffset(endTimeOffset)
};
if (segment.confidence) result.confidence = segment.confidence;
return result;
});
const annotate = async({ featurePack, description, gcsFile }) => {
const startTime = new Date().getTime();
const runId = startTime.toString(32);
const runAt = new Date(startTime).toISOString();
// type(s) of annotations
const { features} = featurePack;
console.debug('initializing', features.join(','));
const request = {
features,
inputUri: gcsFile
};
console.log('starting', runId, description, runAt);
// the result of the long running operation will resolve here
const operationResult = await doLong(request);
// get the annotations
const [annotations] = operationResult.annotationResults;
const elapsed = new Date().getTime() - startTime;
console.log('annotation done after ', elapsed / 1000);
return {
annotations,
runId,
runAt,
elapsed,
gcsFile,
description
};
};
// do a labelling request
const processVideo = async ({ fileName, description, videoFile }) => {
const gcsFile = `gs://${viBucket}/${videoFile}`;
// do the annotation
const annotationResult = await annotate ({
featurePack: configs.all,
description, gcsFile
});
const { annotations, runId, elapsed, runAt } = annotationResult;
// get the data for this type
const {
segmentLabelAnnotations,
shotLabelAnnotations,
shotAnnotations,
faceAnnotations,
textAnnotations,
speechTranscriptions,
logoRecognitionAnnotations,
error
} = annotations;
// package up
const result = {
errorCode: error ? error.code : null,
errorMessage: error ? error.message : 'success',
description,
runId,
runAt,
elapsed,
gcsFile,
fileName,
shotLabels: makePack({ items: shotLabelAnnotations }),
segmentLabels: makePack({ items: segmentLabelAnnotations }),
shotSegments: makeSegments({ segments: shotAnnotations }),
textSegments: makeTextPack({ items: textAnnotations }),
};
return result;
};
return {
init,
processVideo
};
})();
Confidence
By default, the confidence level in the UI is 75%, but all annotation labels are stored in the database. We see a lot more labels when the slider is moved to 20%. I’m not sure what the best setting is for this yet.

What else
Dealing with different versions of a video and identifying if they are indeed the same can be very hard. Of course if they are the same encoding and exactly the same cut (in other words the exact same file), then you can use the md5 digest, but more often than not they won’t be. Using labelling, confidence scores and shot changes can be a good way to de-deuplicate different formats or even cuts of the same film. But that’s for another post.
More
Since G+ is closed, you can now star and follow post announcements and discussions on github, here