The problem with rate limits
You’ve most likely hit the problem of rate-limited APIS at some point. You make a request and it gets refused because you’ve done too many requests in some time period. Fair enough, there are many techniques (you’ll find various approaches elsewhere on this site) to deal with this but usually it’s after the event. You try something, it fails, you wait a bit, you try again – repeat till it works. Some APIS have the decency to give you details about how long to wait before trying again (Vimeo is a good example of this). However, this all can be a real pain when
- The requests you are making are asynchronous and uncontrollable
- You are using a paid-for API and have to pay for usage even if rejected
- There are multi-layers to the rate-limiting – for example a per minute rate and perhaps a monthly limit too – retries to defeat the per minute rate get added to your monthly usage
- If you are using pubsub, which will publish another attempt just as you are trying to deal with the previous rate limit failure, so you process that one too, and it all spirals into a recursive set of activities that achieve nothing at all.
An approach
Being able to queue requests and feed them in a controlled way is a great way to avoid rate limit failures before they happen, rather than deal with them after they’ve happened. My goto for all matters asynchronous is always Sindre Sorhus who has some awesome repositories for this kind of stuff. In this case, I’m using p-queue as the basis for an asynchronous queuing solution.
The problem
The Video Intelligence API
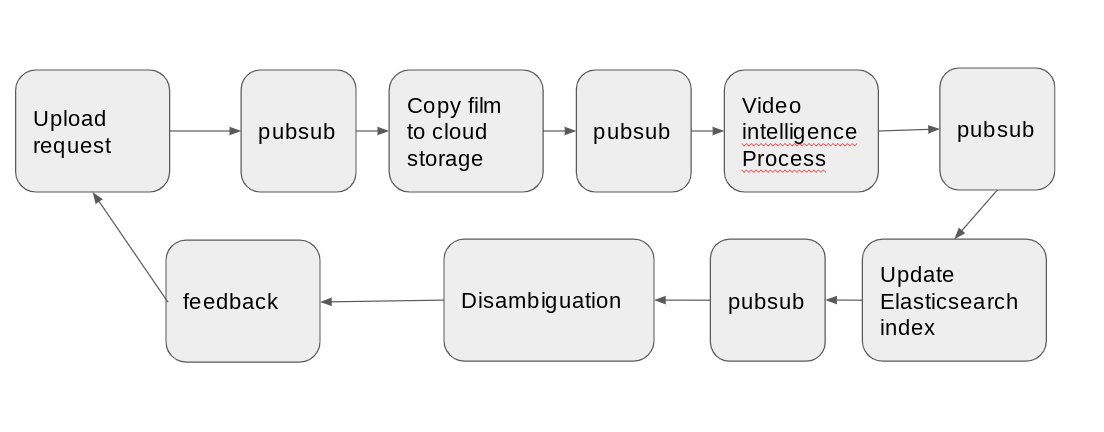
- The processing runs as a long-running API task – a black box – that either works or doesn’t. If it fails due to a 429 (rate-limit – per minute) problem, the run is wasted, you have to start again – and pay again. At over $1 a minute, this can really mount up.
- Pubsub requests could be arriving at any time. If there are multiple failures, they may be delivered multiple times, making things even worse.
- Everything is asynchronous
Queuing
Here’s where a queue comes in handy. The p-queue code almost worked straight out of the box, except that I also needed deduplication to discard multiple pubsub requests when it was becoming impatient for a message ack. The characteristics I need are
- Limit a certain number of runs in a given interval
- Limit the number of concurrent runs
- Deduplication of requests already queued up to do the same thing, either because of a failure retry or the same film was submitted multiple times.
- Introduce logging
pq
I made a wrapper for p-queue to add the extra stuff I needed. Here’s the code
const {
default: PQueue
} = require('p-queue');
// this is needed to avoid quota problems with vint
// just do one at a time
// options to not add it if it's already in the queue
const pq = ((ns) => {
ns.init = (options) => {
ns.options = options || {};
ns.tracker = new Set();
ns.queue = new PQueue({
...options,
concurrency: ns.options.concurrency || 1
});
if (ns.options.logEvents) {
ns.queue.on('idle', () => {
console.log(`....queue is now empty`);
});
}
console.log('....initialized queuing system');
};
ns.add = (fn, options) => {
// first check to see if we are avoiding duplication
const {
digest,
skipIsError,
log
} = options || {};
const addedToQueue = new Date().getTime();
// the idea is to only run things that are not in the queue already - the digest differentiates them
// (if dedup is set and a digest is supplied)
if (!ns.options.dedup || !digest || !ns.tracker.has(digest)) {
// this marks that this item is already queued or running
if (digest) ns.tracker.add(digest);
if (log) console.log(`....adding ${digest || 'item'} to queue at position ${ns.queue.size + 1}`);
// now add to the queue proper
return ns.queue.add(fn)
.then(result => {
const finishedAt = new Date().getTime();
const elapsed = finishedAt - addedToQueue;
const mess = `....${digest|| 'item'} completed ${elapsed} ms after being added to queue`;
if (log) console.log(mess);
const rob = {
digest,
result,
finishedAt,
addedToQueue,
elapsed,
error: null,
skipped: false
};
// all done so remove this digest marker
if (digest) ns.tracker.delete(digest);
return rob;
})
.catch(err => {
console.log('... queue detected an error for', digest, err);
if (digest) ns.tracker.delete(digest);
return Promise.reject(err);
});
} else {
const error = `${digest} already in queue ... skipped`;
if (log) console.log(error);
// if skip is being treated as an error signal it, otherwise resolve it but with a skipped flag
return skipIsError ? Promise.reject({
error,
skipped: true,
digest
}) : Promise.resolve({
error,
skipped: true,
digest
});
}
};
return ns;
})({});
module.exports = {
pq
};
Of note are the use of a digest to identify a queue insertion so that duplicates can be detected, and the ability to treat a dup as a cause for concern or part of normal operation. In the vi processor itself, it’s a straightforward asynchronous queue with single concurrency. When one finishes the other starts.
Initialize it like this
// start the queue
pq.init({
logEvents: true,
log: true,
dedup: true
});
Add items to the queue like this, passing a digest to uniquely identify what this request is doing with which film to be used as a duplicate detector. When the queue item (action()) is finally resolved the pubsub messaged is asked (according to the returned consume property), and it’s all over. If the item is skipped it means it’s already in the queue so we don’t want to tell pubsub to stop sending messages in case the queued version subsequently fails.
return pq.add (()=>action(), {
// no point in doing the same film again if its already in the queue - mightbe caused by multiple pubsub timeouts
digest: hasher({
filmMasterID,
features: features || 'none',
uploadVideoFile
})
}).then(r=>{
if(r.skipped) {
console.debug(
`....already running ${pack.filmName} (${pack.filmID}/${pack.filmMasterID}) - skipping`);
} else {
console.debug(
`finally ${pack.filmName} (${pack.filmID}/${pack.filmMasterID}) dequeued at ${r.finishedAt.toString()} after ${r.elapsed/1000}s`);
}
return {
consume: !r.skipped
};
});
Bulk processing
Normally the occasional film needs processing, but you may want to do some operation that analyzes thousands of films. In this case, we don’t want to leave it to the processor to handle duplicates and queueing, because pubsub will be going crazy waiting for its messages to be consumed while they are all waiting in the queue to be consumed one by one. In this case, we need a queue for a queue, which only provokes and analysis request according to some schedule. We can use the same pq module to accomplish this.
This time we want to provoke ‘intervalCap’ instances concurrently in any ‘interval’. In my case – this turns out to be 1 every 120 seconds.
pq.init({
logEvents: true,
log: true,
dedup: true,
intervalCap: options.intervalCap,
// expects milliseconds
interval: options.interval * 1000
});
The task this time is to send a request to pubsub to process another film. The processor will either do it right away or add it to the queue – but because the bulk updater is itself throttling requests it will receive them in an orderly enough way to be able to deal with them tidily.
return pq.add (()=>task(), {
digest:f.filmMasterID,
})
.then(result=>{
console.log('..executed ' + f.filmMasterID);
});
Running bulk
Just to finish this topic, all the stages, including my back end database and graphql api, run as Kubernetes deployments, but the bulk processing submitter itself can also run as a Kubernetes job – which gets it off your desktop. My bulk processor is a node app, so I can create an image, push it to the container registry and kick it off with.
kubectl create job fid-vibulk-kp --image=gcr.io/fid-prod/fid-vibulk-kp
And that’s it – handling asynchronous tasks and avoiding rate limits before they happen.