Identify Duplicates on Google Drive
The problem with Drive is that it’s really easy to have loads of files with the same name spread around in multiple folders on Drive. Here’s how to get a handle on that by identifying duplicates, without having to write a bunch of code.
I’ll be using the cUseful library, specifically these techniques.
Here’s the key for the cUseful library, and it’s also on GitHub, or below.
Mcbr-v4SsYKJP7JMohttAZyz3TLx7pV4j
The objective is to write a report to a spreadsheet of files that are duplicates. On my private version of this, I also have an algorithm for cleaning them up, but I’m not releasing that for now as I don’t want you to accidentally delete files you didn’t want to, so this version concentrates on reporting on duplicates.
It’s pretty slow to look through thousands of files organized by many folders, so you may need to do it in chunks by using the /path setting, as well as particular mimetypes, and perhaps by using the search terms too.
I’m using caching to avoid reading the folder structure too many times. It’s a big job to do that, so the first time you do it it will take a while. If your folder structure is not changing much, you can set the cache stay alive time to a higher number.
Settings
It starts with the settings, which look like this
var Settings = (function(ns) {
ns.drive = {
dapi:DriveApp, // Use DriveApp api
startFolder:'/', // folder path to start looking
mime:"application/vnd.google-apps.script", // mime type to look for
recurse:true, // whether to recurse through folders
acrossFolders:true, // whether to count files with same name in different folders as duplicate
acrossMimes:false, // whether to count files with same name but different mimes as the same
useCache:true, // whether to use cache for folder maps
cacheSeconds:60*60, // how long to allow cache for
search:"" // can use any of https://developers.google.com/drive/v3/web/search-parameters
};
ns.report = {
sheetId:"1Ef4Ac5KkipxvhpcYCe9C_sx-TnD_kvV2E_a211wS6Po", // sheet id to write to
sheetName:'dups-'+ns.drive.startFolder+"-"+ns.drive.mime, // sheetName to write to
min:2 // min count to report on
};
return ns;
})(Settings || {});
Here’s an example output. Here I can see duplicate files names for scripts across folders.
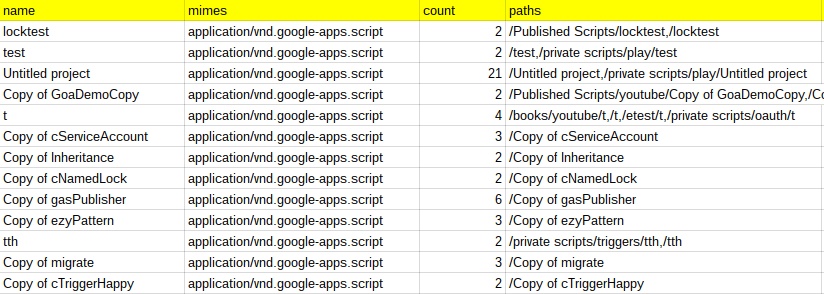
Some notes on the Settings
- drive.dapi – This is always DriveApp in this version. It can also use advanced Drive service , but strangely it is slower than DriveApp. I may implement different APIS in a future version.
- drive.startFolder – the folder to start looking. This is a path like /documents/abc/. The drive root is /. If you find yourself running out of run time quota then you’ll have to do it in chunks by path specification.
- drive.mime – use a standard mime type. If you leave it blank then all files will be considered
- drive.recurse – If false, only the start folder is looked at. If true, all the subfolders are included.
- drive.acrossFolders – if true then a file with the same name in a different folder is considered to be a duplicate.
- drive.acrossMimes – if true then a file with the name but a different mime type is considered to be a duplicate.
- drive.useCache – if true, then the folder structure is retrieved from cache (if available) rather than being built from drive
- drive.cacheSeconds – how long to make cache last for. If not much change you can make this big.
- drive.search – you can use any of the api search terms to further filter the search. If you have specified a value for drive.mime that is added to this search term.
- report.sheetID – the sheet to write the results to.
- report.sheetName – the sheet name to write the results to.
- report.min – the minimum number of duplicates to be included in the report. The thing that slows it down is to find the parents of a file in order to figure out its path, so the first thing it does is to remove all files that haven’t got enough name repetitions to qualify for the report. Making this 1 will enumerate the drive, but will take a long time since every file will be fully processed, so be careful of quota blowing.
Example settings
Find duplicate file names ignoring mimetypes and folders, but starting at the given startFolder
ns.drive = {
dapi:DriveApp, // Use DriveApp api
startFolder:'/Published Scripts', // folder path to start looking
mime:"", // mime type to look forapplication/vnd.google-apps.script
recurse:true, // whether to recurse through folders
acrossFolders:true, // whether to count files with same name in different folders as duplicate
acrossMimes:true, // whether to count files with same name but different mimes as the same
useCache:true, // whether to use cache for folder maps
cacheSeconds:60*60, // how long to allow cache for
search:"" // can use any of https://developers.google.com/drive/v3/web/search-parameters
};
ns.report = {
sheetId:"1Ef4Ac5KkipxvhpcYCe9C_sx-TnD_kvV2E_a211wS6Po", // sheet id to write to
sheetName:'dups-'+ns.drive.startFolder+"-"+ns.drive.mime, // sheetName to write to
min:2 // min count to report on
};
Find all files containing test in the name of any mime type
ns.drive = {
dapi:DriveApp, // Use DriveApp api
startFolder:"/", // folder path to start looking
mime:"", // mime type to look for
recurse:true, // whether to recurse through folders
acrossFolders:true, // whether to count files with same name in different folders as duplicate
acrossMimes:true, // whether to count files with same name but different mimes as the same
useCache:true, // whether to use cache for folder maps
cacheSeconds:60*60, // how long to allow cache for
search:"title contains 'test'" // can use any of https://developers.google.com/drive/v3/web/search-parameters
};
ns.report = {
sheetId:"1Ef4Ac5KkipxvhpcYCe9C_sx-TnD_kvV2E_a211wS6Po", // sheet id to write to
sheetName:'dups-'+ns.drive.startFolder+"-"+ns.drive.mime, // sheetName to write to
min:1 // min count to report on
};
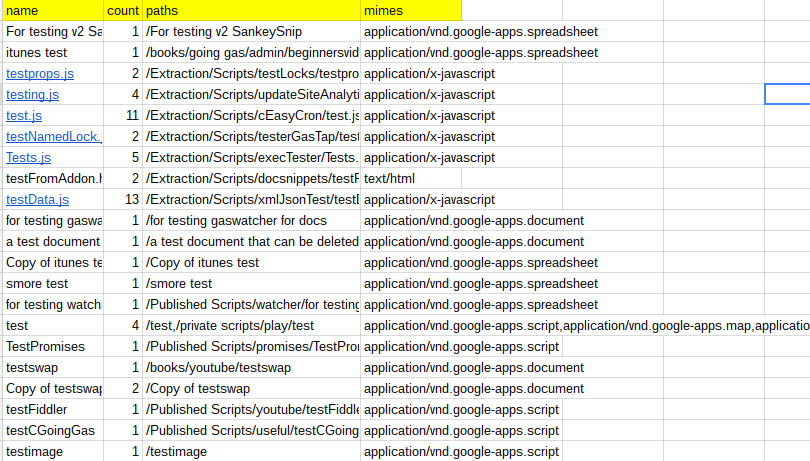
The code
It’s on GitHub, or below, or copy of developing version here. You’ll need the settings namespace at the beginning of this post too.
/**
* figure out dups on drive
* see settings namespace for parameters
* to try to minimize quota usage
* the approach is to weed out as much as posible
* before looking at the folders/file relationship
*/
function dupsOnMyDrive() {
// the settings
var se = Settings.drive;
var sr = Settings.report;
var fiddler = new cUseful.Fiddler();
var cache = CacheService.getUserCache();
// get the start folder
var startFolder = cUseful.DriveUtils
.setService(DriveApp)
.getFolderFromPath (se.startFolder);
// get all the folders that are good
var cacheKey = cUseful.Utils.keyDigest (se.startFolder, "driveCleaning");
var cached = se.useCache ? cache.get(cacheKey) : null;
var allFolders = cached ? JSON.parse(cUseful.Utils.uncrush(cached)) :
getEligibleFolders(startFolder,se.startFolder) ;
// using cache , but zipping
// only rewrite if not found in cache
if (!cached) {
cache.put (cacheKey , cUseful.Utils.crush (allFolders), se.cacheSeconds);
}
// now get all the files on Drive of this mimetype
if (se.search) {
var searchTerm = se.search + (se.mime ? " and mimeType = '" + se.mime +"'": "");
var files = cUseful.Utils.expBackoff (function () {
return DriveApp.searchFiles(se.search);
});
}
else {
var files = cUseful.Utils.expBackoff (function () {
return se.mime ? DriveApp.getFilesByType(se.mime) : DriveApp.getFiles();
});
}
// get them as a pile
var smallerPile = getAllTheFiles (files);
// write the data to the sheet
var ss = SpreadsheetApp.openById(sr.sheetId);
var sh = ss.getSheetByName(sr.sheetName);
// if if does exist, create it.
if (!sh) {
sh = ss.insertSheet(sr.sheetName);
}
// clear it
sh.clearContents();
// set up the data to write to a sheet
if (Object.keys(smallerPile).length) {
fiddler.setData (Object.keys(smallerPile).map(function(k) {
return smallerPile[k];
}))
.filterRows(function (row) {
// only report on those that are above the threshold
return row.count >= sr.min;
})
.mapRows(function (row) {
row.paths = row.paths.join(",");
row.mimes = row.mimes.join(",");
return row;
})
.filterColumns (function (name) {
// dump the id and the key and the path
return name !== "id" && name !== "key" && name !== "path" && name !== "mime";
})
.getRange(sh.getDataRange())
.setValues(fiddler.createValues());
}
// get all the folders that are below the start folder
function getEligibleFolders(startFolder,path,allFolders) {
allFolders = allFolders || [];
var foldit = startFolder.getFolders();
var folders = [];
while (foldit.hasNext()) {
folders.push(foldit.next());
}
// add the parent folder
allFolders.push (getFob(startFolder, path));
// recurse
if (se.recurse) {
folders.forEach (function (d) {
return getEligibleFolders (d, path+d.getName()+"/", allFolders);
});
}
function getFob(folder,path) {
return {
id:folder.getId(),
name:folder.getName(),
path:path
};
}
return allFolders;
}
/**
* get all the files but drop those that there are less than threshold
* @param {FileIterator} files the files
* @return {Array.object} the files
*/
function getAllTheFiles (files) {
// list of files will be here
var pile = [];
// that just makes them easier to dealwith
while(files.hasNext()) {
var file = files.next();
pile.push(file);
};
// now make an object keyed on the the names
var fileOb = pile.reduce (function (p,c) {
var key = se.acrossMimes ? c.getName() : c.getName() + c.getMimeType() ;
if (!p.hasOwnProperty(key)) {
p[key] = {
file:c,
key:key,
count:0
}
}
p[key].count++;
return p;
},{});
// make a reduced pile, of files that are potential dups
// and add the parents
var reducedPile = pile.map(function (d) {
var key = se.acrossMimes ? d.getName() : d.getName() + d.getMimeType() ;
return fileOb[key].count >= sr.min ? d : null;
})
.filter(function(d) {
return d;
})
.map(function(d) {
// now get the parents
var parents = [];
var parentIt = d.getParents();
while (parentIt.hasNext()) {
var parent = parentIt.next();
var targets = allFolders.filter(function(e) {
return parent.getId() === e.id;
});
// now store those parents
targets.forEach(function(e) {
parents.push (e);
});
}
// if this is true, then its an interesting file
var key = se.acrossMimes ? d.getName() : d.getName() + d.getMimeType() ;
var fileOb = parents.length ? {
id:d.getId(),
name:d.getName(),
mime:d.getMimeType(),
path:parents[0].path + d.getName(),
key: se.acrossFolders ? key : parents[0].id + key
} :null;
if (parents.length > 1) {
Logger.log(fileOb.path + ' had ' + parents.length + ' parents: only used the first');
}
return fileOb;
})
.filter (function(d) {
// filter out those that were not of interest
return d;
});
// finally, if we need to take account of folders to weed out dups, then do all that again
// now that we know the parents
var fileOb = reducedPile.reduce (function (p,c) {
if (!p.hasOwnProperty(c.key)) {
p[c.key] = c;
c.count = 0;
c.paths = [];
c.mimes = [];
}
p[c.key].count++;
// concat paths/mimes if more than one
if (!p[c.key].paths.some(function (d) { return c.path === d; })) {
p[c.key].paths.push(c.path);
}
if (!p[c.key].mimes.some(function (d) { return c.mime === d; })) {
p[c.key].mimes.push(c.mime);
}
return p;
},{});
// further weed out
return Object.keys (fileOb).map(function (d) {
return fileOb[d].count >= sr.min ? fileOb[d] : null;
})
.filter (function(d) {
return d;
});
}
}