There are limits on Drive file size that’s it’s hard to get past – so you sometimes can’t just dump it out and load it using the bigquery console tools, and also BigQuery takes something called delimited JSON as input – so you do have to do a little tweaking.
Apps Script does have a BigQuery advanced service, but it also has a 10mb limit on data that can be loaded. However it’s easy to load data in multiple stages. Here’s how.
Creating a dataset
You have to enable billing to use BigQuery, so use a developer console project that has it enabled. Just select the project in the big query console at https://bigquery.cloud.google.com
Add a dataset and pick an Id. In this example, I’ve created a dataset called jeopardydata. It’s going to hold more or less all the jeopardy questions ever asked . I came across it here on Reddit.
Creating a table
Within datasets. you can have tables,and you’ll be tempted to create one here. However, I’ll create a table when I load the data so we’re done in the bigquery console for now.
Creating a table will need a table reference object – it looks like this. By default, a load operation will create the table if it doesn’t already exist.
var tableReference = {
projectId: "lateral-command-416",
datasetId: "jeopardydata",
tableId: "questions"
};
Enabling BigQuery
You’ll need to enable the advanced service for BigQuery, and also enable it in the target project.
The Schema
When creating a table, you need to also make a schema to describe the data to expect. The data types don’t exactly match the JavaScript types, but for my data, which is flat and simple, I only need to enable 3 types, driven by this object.
// These are the data types I'll support for now.
var bqTypes = {
number:"FLOAT",
string:"STRING",
bool:"BOOLEAN"
};
The Data
My source data is a 53mb Drive file, and is a JSON array of objects that looks like this.
[{
"category": "HISTORY",
"air_date": "2004-12-31",
"question": "'For the last 8 years of his life, Galileo was under house arrest for espousing this man's theory'",
"value": "$200",
"answer": "Copernicus",
"round": "Jeopardy!",
"show_number": "4680"
}, ... ]
BigQuery needs JSON delimited data, so I’ll use Apps Script to transform and load the data directly.
I’m confident that the objects in each array element are consistent, so I’ll just use the first row to create the fields for the schema
var model = data[0];
var fields = Object.keys(model).reduce(function(p,c) {
var t = typeof model;
if (!bqTypes[t]) {
throw 'unsupported type ' + t;
}
p.push ( {name:c, type: bqTypes[t]} );
return p;
},[]);
The Jobs
Since my data is larger than 10mb, I have to load it in chunks, whilst at the same time transforming it from an array of objects, into new line delimited JSON.
Here’s how – I’ve actually limited my chunk size to 8mb in this example.
// there is a max size that a urlfetch post size can be
var MAX_POST = 1024 * 1024 * 8;
// now we can make delimted json, but chunk it up
var chunk = '', jobs = [];
data.forEach (function (d,i,a) {
// convert to string with "\n"
var chunklet = JSON.stringify(d) + "\n";
if (chunklet.length > MAX_POST) {
throw 'chunklet size ' + chunklet.length + ' is greater than max permitted size ' + MAX_POST;
}
// time to flush?
if (chunklet.length + chunk.length > MAX_POST) {
jobs.push ( BigQuery.Jobs.insert(job, tableReference.projectId, Utilities.newBlob(chunk)) );
chunk = "";
// after the first , we move to append
job.configuration.load.writeDisposition = "WRITE_APPEND";
}
// add to the pile
chunk += chunklet;
});
// finish off
if (chunk.length) {
jobs.push ( BigQuery.Jobs.insert(job, tableReference.projectId, Utilities.newBlob(chunk)) );
}
Progress
Once kicked off, you can find progress of your jobs in the BigQuery console. It looks like this when complete.
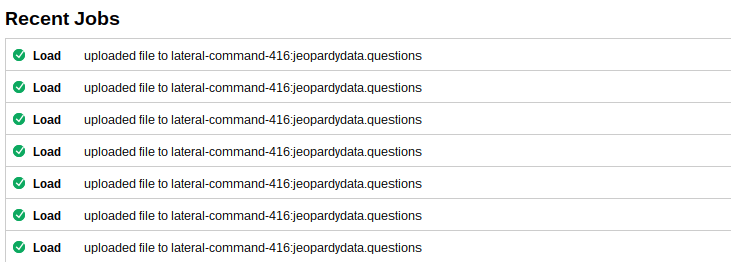
Each load looks like this

You can do queries in the console – this shows me how many were loaded.
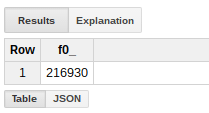
And here’s a preview of the data in BigQuery

The code
The entire code is below. The file shown is public so you can use it if you like. You’ll need to change the project id to one of your own. It takes quite a while so you may need to modify it to do it a section at a time.
function makeBigQueryFileFromDrive() {
// get the file questions
var file = DriveApp.getFileById("0B92ExLh4POiZbXB0X2RDWXZqLTA");
// get the data
var data = JSON.parse (file.getBlob().getDataAsString());
// this will create this table if needed
var tableReference = {
projectId: "lateral-command-416",
datasetId: "jeopardydata",
tableId: "questions"
};
// load it to bigquery
var jobs = loadToBigQuery (tableReference, data);
Logger.log(jobs);
// keep an eye on it
Logger.log('status of job can be found here: https://bigquery.cloud.google.com/jobs/' + tableReference.projectId);
}
function loadToBigQuery (tableReference,data) {
// These are the data types I'll support for now.
var bqTypes = {
number:"FLOAT",
string:"STRING",
bool:"BOOLEAN"
};
// figure out the schema from the JSON data- assuming that the data is all consistent types
var model = data[0];
var fields = Object.keys(model).reduce(function(p,c) {
var t = typeof model;
if (!bqTypes[t]) {
throw 'unsupported type ' + t;
}
p.push ( {name:c, type: bqTypes[t]} );
return p;
},[]);
// the load job
var job = {
configuration: {
load: {
destinationTable: tableReference,
sourceFormat: "NEWLINE_DELIMITED_JSON",
writeDisposition: "WRITE_TRUNCATE",
schema:{
fields:fields
}
},
}
};
// there is a max size that a urlfetch post size can be
var MAX_POST = 1024 * 1024 * 8;
// now we can make delimted json, but chunk it up
var chunk = '', jobs = [];
data.forEach (function (d,i,a) {
// convert to string with "\n"
var chunklet = JSON.stringify(d) + "\n";
if (chunklet.length > MAX_POST) {
throw 'chunklet size ' + chunklet.length + ' is greater than max permitted size ' + MAX_POST;
}
// time to flush?
if (chunklet.length + chunk.length > MAX_POST) {
jobs.push ( BigQuery.Jobs.insert(job, tableReference.projectId, Utilities.newBlob(chunk)) );
chunk = "";
// after the first , we move to append
job.configuration.load.writeDisposition = "WRITE_APPEND";
}
// add to the pile
chunk += chunklet;
});
// finish off
if (chunk.length) {
jobs.push ( BigQuery.Jobs.insert(job, tableReference.projectId, Utilities.newBlob(chunk)) );
}
return jobs;
}