The report
You get 1 report, which summarizes all the files that need attention into one row per file, with a reorganization of the layout of the hosted files so they can easily be loaded to the new hosting place – whichever method you choose. At this stage, it’s independent of that. The filePath below is how the files will be re-organized. No files are copied yet – that’ll happen in the next phase, but this is how it proposes to re-organize the googledrive hosted files. Note that it works with both googledrive.com/host/folderid/name and googledrive.com/host/fileid variations.
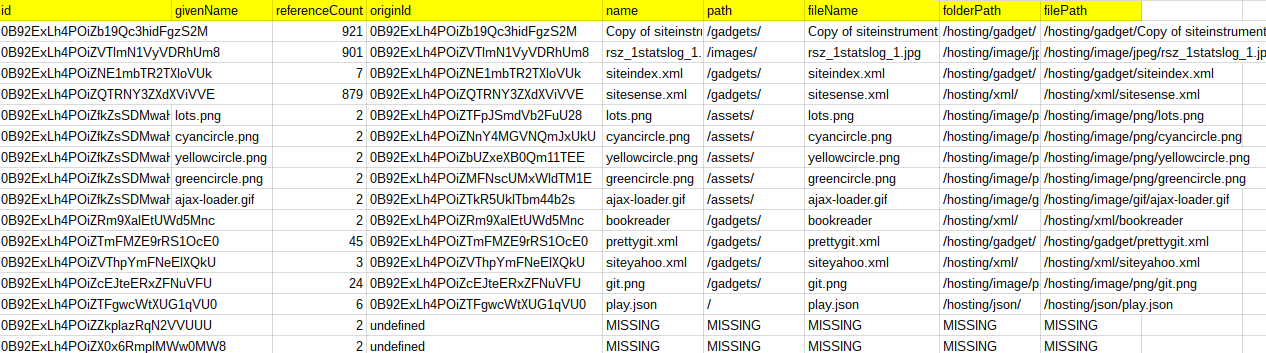
This report is used as input to the next phase, Copying to new host location
cUseful library
I’ll be using the cUseful library, specifically this techniques.
Here’s the key for the cUseful library, and it’s also on github, or below.
Mcbr-v4SsYKJP7JMohttAZyz3TLx7pV4j
Settings
It starts with the settings, which have been expanded to now look like this, and we’re mainly concerned with the Settings.identify section.
var Settings = (function(ns) {
ns.sites = {
search:"", // enter a search term to concentrate on particular pages
siteName:"share", // site name
domain:"mcpher.com", // domain
maxPages:0, // max pages - start low to test
maxChunk:200 // max children to read in one go
};
ns.report = {
sheetId:"19kXFMUh0DNTde_qtvsZ6FH4dAJ4YDCJhIJroLNT3vGY", // sheet id to write to
sheetName:'site-' + ns.sites.domain + '-' + ns.sites.siteName, // sheetName to write to
sheetHosting:'hosting-' + ns.sites.domain + '-' + ns.sites.siteName
};
ns.identify = {
sheetId:ns.report.sheetId, // where to write the results
sheetFiles:"identify-" + ns.report.sheetHosting,
treatments: {
fileName:"{name}", // template for output file name - can be {id}-{name}
path:"/hosting/{mime}/", // template for file path can be {id}-{name}-{drivePath}-{mime}
failOnMissing:false, // whether to fail if file is missing
missingText:"MISSING"
}
};
return ns;
})(Settings || {});
Some notes on the settings
- This will create a new sheet, so sheetId and sheetFiles say where.
- treatments are how to handle situations and to organize the files
- filename is a template to construct the new file name- It can be any text you like, and you can also include the {id} and {name} somewhere in the new file name, where id and name are the values for the current file.
- path is an output path describing the folder structure the new files will end up. Here you can use any text plus {id},{name},{drivePath} and {mime} where id and name refer to the name and id of the current file, drivePath is the path of its current folder and mime is an abbreviated form of its mime type.
- failOnMissing – if a file is missing and this is true it will stop processing
- missingText – is the text to use for a filename if it the file is missing
The code
It’s on GitHub, or below, or copy of developing version here. You’ll need the settings namespace at the beginning of this post too and of course the cUseful library reference.
/**
* copy the matched files from
* sheet created in look for hosting
* make a new sheet with their new names
*/
function identifyHostingFiles () {
// get the data
var sr = Settings.report;
var si = Settings.identify;
//DriveApp.getFileById(id)
var du = cUseful.DriveUtils.setService(DriveApp);
var fiddler = new cUseful.Fiddler();
fiddler.setValues (
SpreadsheetApp.openById(sr.sheetId)
.getSheetByName(sr.sheetHosting)
.getDataRange()
.getValues()
);
// map the file names
var work = fiddler.getData().reduce(function (p,c) {
// this may be a folder/filename kind of deal
if (!p.files.hasOwnProperty(c.id + c.fileName)) {
// now find the file
var file = du.getFileById (c.id);
var fob = p.files[c.id+c.fileName] = {
id:c.id,
givenName:c.fileName
};
fob.referenceCount = 0;
if (file) {
// if its the folder/name model, then we're not yet done
if (c.fileName && du.getShortMime(file.getMimeType()) !== "folder") {
// this is going to be a missing file
file = null;
}
else if (du.getShortMime(file.getMimeType()) === "folder") {
// in this cae the id refers to the parent.
var folder = DriveApp.getFolderById(file.getId());
file = folder.getFilesByName(c.fileName);
if (!file.hasNext()) {
file = null;
}
else {
file = file.next();
}
}
}
if (file) {
fob.originId = file.getId();
fob.name = file.getName();
fob.path = du.getPathFromFolder(file.getParents().next());
// set up the new names and paths
fob.fileName = si.treatments.fileName
.replace(/\{id\}/g,fob.id)
.replace(/\{name}/g,fob.name);
fob.folderPath = si.treatments.path
.replace(/\{id\}/g,fob.id)
.replace(/\{drivePath}/g,fob.path)
.replace(/\{mime}/g,du.getShortMime(file.getMimeType()));
fob.filePath = fob.folderPath + fob.fileName;
// what to do if we already have this file path?
if (p.paths.hasOwnProperty(fob.filePath)) {
if (p.paths[fob.filePath].id !== file.getId()) {
throw new Error('Would create ambigous filepath for ' + file.getId() + ' ' + fob.filePath);
}
}
else {
p.paths[fob.filePath] = file.getId();
}
}
else {
if (si.treatments.failOnMissing) {
throw new Error ('cant find file id ' + c.id + " " + c.fileName);
}
fob.name = fob.path = fob.filePath = fob.fileName = fob.folderPath = si.treatments.missingText;
}
}
p.files[c.id+c.fileName].referenceCount++;
return p;
},{files:{}, paths:{}});
// copy them to new location
// write out the result to a new sheet
var ss = SpreadsheetApp.openById(si.sheetId);
var sh = ss.getSheetByName(si.sheetFiles);
// if if does exist, create it.
if (!sh) {
sh = ss.insertSheet(si.sheetFiles);
}
// clear it
sh.clearContents();
var fileFiddler = new cUseful.Fiddler();
fileFiddler.setData(Object.keys(work.files).map(function(k) {
return work.files[k];
}))
.filterColumns(function (name) {
// get rid of stuff not required
return name !== "url" && name !== "index";
})
.getRange(sh.getDataRange())
.setValues(fileFiddler.createValues());
}