Rough Matching
When dealing with matching in sheets, you sometimes need to get close matches. This post shares the “Rough” namespace of the cUseful library, available here.
Some examples
Let’s start with this sheet – a Sean Connery filmography. The objective is to find rows that roughly match some text, to be provided later.
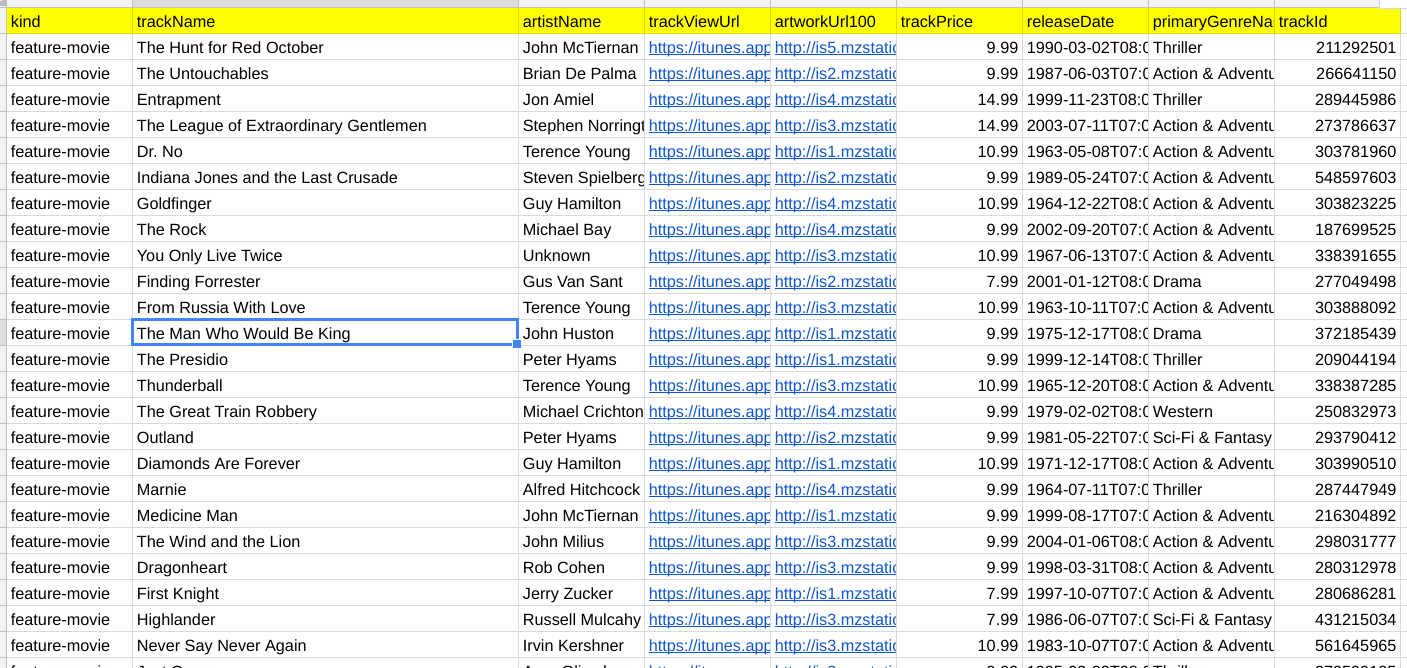
I’m using fiddler to handle sheet interactions because it makes manipulation so much easier. You can of course access your sheet in other ways, but I won’t cover that here, so let’s start by getting the sheet contents and objectifying.
const fiddler = new cUseful.Fiddler(SpreadsheetApp.getActiveSheet());
Now we need to set up rough matching. I’m going to set up a reference list using the trackName column – but this could be any list or combination of column data. Matching of any sort can return more than 1 result. The rough matcher assigns a value of 0-1, and returns the results in order, with the most likely match first. I’m setting the minimum score level to 0.3, so anything below that score will be discarded.
const data = fiddler.getData();
// build a reference list of film names
const rough = new cUseful.Rough().init({
min:0.3
}).setReferenceList (data, function(row) {
return row.trackName;
});
Testing
We’re now ready to go – here’s a series of rough matches, with the most likely result logged out
// find things
Logger.log (rough.matcher ("hunt october")[0].row.phrase);
Logger.log (rough.matcher ("october red hunts")[0].row.phrase);
Logger.log (rough.matcher ("no dr")[0].row.phrase);
Logger.log (rough.matcher ("russia house")[0].row.phrase);
Logger.log (rough.matcher ("russian")[0].row.phrase);
Logger.log (rough.matcher ("robin hooding")[0].row.phrase);
the results
the hunt for red october the hunt for red october dr no the russia house the russia house robin hood prince of thieves
Umlats and accents
Many languages have accents in the spelling. These are dealt with too.
// with umlats
Logger.log (rough.matcher ("röbbin höüding")[0].row.phrase);
result
robin hood prince of thieves
Getting matching rows
Often (as with vlookup), you’ll want to get the matching value from another part of the matched row. Rough match returns an index that can be used to index into the original data that was used to set up the reference list.
// use as index
Logger.log(data[rough.matcher ("forever diamond")[0].index].artistName);
result
Guy Hamilton
Multiple results
Here’s how you would get the top 3 results, with their scores
// top 3
Logger.log (rough.matcher ("russians").slice (0,3).map(function (r) {
return data[r.index].artistName +':' + data[r.index].trackName + ':' + r.score;
}));
result
[Fred Schepisi:The Russia House:0.5431034482758621, Terence Young:From Russia With Love:0.5, Philip Kaufman:Rising Sun:0.4649122807017544 ]
Options
There are plenty of options to tweak the algorithm. It’s fairly easy to figure out what they do so I’ll leave you to play. You pass tweaked options when you .init() the Rough object. (In the example earlier, I tweaked the min value). Here are all the available options at time of writing.
const CLEANER_OPTIONS = {
stem: true,
stub: true ,
unAccent: true,
stopwords: true,
language: "en",
extraStops:[],
min:0.6,
scores: {
stubMatch: 10,
stubPenalty: -1,
stemMatch: 12,
stemPenalty: -1,
wordMatch: 20 ,
wordPenalty: -1,
orderMatch: 1,
stubPartialMatch: 40,
stubPartialPenalty: -7,
initialMatch: 3,
initialPenalty: -4,
reverseMatch: 2,
reversePenalty: -4
}
};
Stemming
This refers to changing words to their stem – for example director, direction, directors, directing etc all have the same stem. Stemming is a common process to normalize text for input to AI.
Stubbing
This is a technique to simplify the spelling of the stems – so director becomes drctr and so on – which removes most common spelling mistakes.
UnAccent
Removes accents and umlats.
Stopwords
This removes non valuable words like “with”, “and” etc from consideration.
Language
This selects the language to use. This mainly applies to stopwords. Currently only English and French are supported – but it’s easy to add others.
Extrastops
You can add other non-value add words of your own – perhaps your domain contains specific words that are often used but won’t help with matching differentiation.
Scores
These are used by the algorithm to weight the results.
Most of these processes are provided as standalone namespaces in cUseful – for example if you just want to do stemming for some other purpose, you can use the Stemming workspace
Matching across sheets.
Here’s a full example – where the first and last name are provided in fairly poor shape, but get roughly matched as follows.
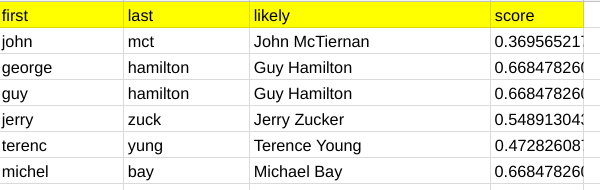
The code
var fiddler = new cUseful.Fiddler(SpreadsheetApp.getActiveSpreadsheet().getSheetByName("films"));
var data = fiddler.getData();
// build a reference list of names
var rough = new cUseful.Rough().init({
min:0.3
}).setReferenceList (data, function(row) {
return row.artistName;
});
// match another sheet
const input = new cUseful.Fiddler (SpreadsheetApp.getActiveSpreadsheet().getSheetByName("input"));
// match to reference
input.mapRows ( function (row) {
const match = rough.matcher ([row.first,row.last].join(" "));
if (match.length) {
row.likely = data[match[0].index].artistName;
row.score = match[0].score;
}
else {
row.likely = row.score = "";
}
return row;
})
.dumpValues();