In this example, I have a large book manuscript with several hundred images I want to extract to Drive with names that reflect which chapter they are in and index them in a spreadsheet.
My starting chapter paragraphs are identified as DocumentApp.ParagraphHeading.HEADING1.
The approach
Using the technique described in Sorting bookmarks in a document, I can identify where all the images and all the paragraphs appear in a document. From this it can easily be deduced which chapter a given image is extracted from.
Code Walkthrough
Setup – it’s a container bound script for the active document.
// where to put the images var IMAGE_PATH = '/books/going gas/admin/draft3/images'; // work on the current document var doc = DocumentApp.getActiveDocument(); var body = doc.getBody();
Identify the paragraphs that are the chapter headers and figure out their chapter numbers and position in document.
// get all the chapter heading level parapgraphs
var chapters = body.getParagraphs().filter(function(d) {
return d.getHeading() === DocumentApp.ParagraphHeading.HEADING1;
})
// and filter out those with no chapter heading text
.filter(function(d) {
var cs = d.getText().split(" ");
return cs.length && cs[0] === 'Chapter';
})
// and attach path in document & chapter number
.map (function(d) {
var cs = d.getText().split(" ");
if (cs.length < 2 ) throw 'no chapter number at ' + d.getText().slice(0,20);
return {element:d , path:pathInDocument (d), chapter:cs[1]};
},[]);
Get all the images and figure out which chapters they are in by comparing their document position with that of each chapter
// now we can use the path in document to decide whether this image is in this chapter
var images = body.getImages().map(function(d) {
var path = pathInDocument (d);
// path of image lies between start of this chapter and beginning of next
var ch = chapters.filter(function (c,i,a) {
return path > c.path && (i === a.length-1 || path < a[i+1].path);
});
// there should be exactly 1 result
if (ch.length !== 1) {
throw 'no chapter found for image at path' + path;
}
// attach chapter object
return {
element:d,
path:path ,
paragraph: ch[0]
};
});
Index each image by its relative position within its chapter – will be used as the figure number and filename
// and add the filename (index by 1 for each chapter)
images.forEach (function(d,i,a) {
d.name = d.paragraph.chapter.toString() + '.' + a.slice(0,i).reduce(function (p,c) {
return c.paragraph.chapter === d.paragraph.chapter ? p+1 : p;
},1).toString();
});
Write them all out, converting them to jpg – this could be preceded by deleting all the files in the receiving folder, but I’ve taken that out for safety in case you use this code as is.
// now write them all out
var folder = getDriveFolderFromPath(IMAGE_PATH);
images.forEach(function(d) {
var blob = d.element.getBlob().copyBlob().setName (d.name+".jpg").setContentTypeFromExtension();
folder.createFile (blob);
});
Record the results to a sheet along with some control information
// index to a sheet
var sheet = SpreadsheetApp.openById('14xFQAdVKzlkujVZDwk27z-632y4FViBKwz-6Iv-UF3U').getSheetByName('figs');
// clear the sheet
sheet.getDataRange().offset(1,0).clearContent();
// write the new values
sheet.getRange(2,1,images.length, 4).setValues(images.map(function(d) {
return [d.name,d.name+".jpg","Screenshot",d.paragraph.element.getText().slice(0,10)];
}));
Utility function for figuring out position in document
function pathInDocument(element,path) {
path = path || '';
var parent = element.getParent();
if (parent) {
path = pathInDocument( parent , Utilities.formatString ( '%04d.%s', parent.getChildIndex(element),path ));
}
return path;
}
Utility function for figuring out Drive folder from folder path name
function getDriveFolderFromPath (path) {
return (path || "/").split("/").reduce ( function(prev,current) {
if (prev && current) {
var fldrs = prev.getFoldersByName(current);
return fldrs.hasNext() ? fldrs.next() : null;
}
else {
return current ? null : prev;
}
},DriveApp.getRootFolder());
}
The output
Here’s a clip of the directory with some of the generated images.

and the index sheet.
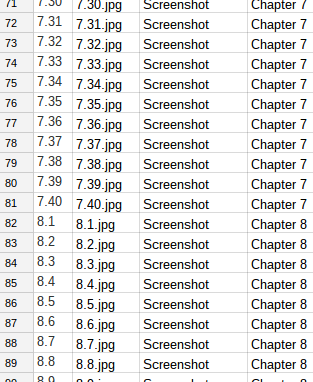
The code
The whole thing
/**
* extract all the figures (images) in a document and name them after the chapter they are in.
*/
function extractFigs() {
// where to put the images
var IMAGE_PATH = '/books/going gas/admin/draft3/images';
// work on the current document
var doc = DocumentApp.getActiveDocument();
var body = doc.getBody();
// get all the chapter heading level parapgraphs
var chapters = body.getParagraphs().filter(function(d) {
return d.getHeading() === DocumentApp.ParagraphHeading.HEADING1;
})
// and filter out those with no chapter heading text
.filter(function(d) {
var cs = d.getText().split(" ");
return cs.length && cs[0] === 'Chapter';
})
// and attach path in document & chapter number
.map (function(d) {
var cs = d.getText().split(" ");
if (cs.length < 2 ) throw 'no chapter number at ' + d.getText().slice(0,20); return {element:d , path:pathInDocument (d), chapter:cs[1]}; },[]); // now we can use the path in document to decide whether this image is in this chapter var images = body.getImages().map(function(d) { var path = pathInDocument (d); // path of image lies between start of this chapter and beginning of next var ch = chapters.filter(function (c,i,a) { return path > c.path && (i === a.length-1 || path < a[i+1].path);
});
// there should be exactly 1 result
if (ch.length !== 1) {
throw 'no chapter found for image at path' + path;
}
// attach chapter object
return {
element:d,
path:path ,
paragraph: ch[0]
};
});
// and add the filename (index by 1 for each chapter)
images.forEach (function(d,i,a) {
d.name = d.paragraph.chapter.toString() + '.' + a.slice(0,i).reduce(function (p,c) {
return c.paragraph.chapter === d.paragraph.chapter ? p+1 : p;
},1).toString();
});
// now write them all out
var folder = getDriveFolderFromPath(IMAGE_PATH);
images.forEach(function(d) {
Logger.log(getDriveFolderFromPath(IMAGE_PATH).getName() + '/' + d.name);
var blob = d.element.getBlob().copyBlob().setName (d.name+".jpg").setContentTypeFromExtension();
folder.createFile (blob);
});
// index to a sheet
var sheet = SpreadsheetApp.openById('14xFQAdVKzlkujVZDwk27z-632y4FViBKwz-6Iv-UF3U').getSheetByName('figs');
// clear the sheet
sheet.getDataRange().offset(1,0).clearContent();
// write the new values
sheet.getRange(2,1,images.length, 4).setValues(images.map(function(d) {
return [d.name,d.name+".jpg","Screenshot",d.paragraph.element.getText().slice(0,10)];
}));
// utitlity functions
function pathInDocument(element,path) {
path = path || '';
var parent = element.getParent();
if (parent) {
path = pathInDocument( parent , Utilities.formatString ( '%04d.%s', parent.getChildIndex(element),path ));
}
return path;
}
function getDriveFolderFromPath (path) {
return (path || "/").split("/").reduce ( function(prev,current) {
if (prev && current) {
var fldrs = prev.getFoldersByName(current);
return fldrs.hasNext() ? fldrs.next() : null;
}
else {
return current ? null : prev;
}
},DriveApp.getRootFolder());
}
}</2></2>