There’s no getting away from the fact that Apps Script is slower than the equivalent client based JavaScript processing. It is fundamentally synchronous in implementation, and also has limits on processing time and a host of other quotas. For a cloud based, free service that’s about extending Drive capabilities rather than being scalable in the manner of Google App Engine, I suppose it’s normal. But let’s see if we can at least subvert at least these two things.
There are other ways to approach parallel running, such as taking advantage of the client processing capability. If you are able to do that, then you should take a look at Running things in parallel using HTML service. The method in this post uses timed triggers which are not very controllable.
- get over the 6 minute maximum execution time for Apps Script
- run things in parallel
Latest news – There’s a new and improved version of this over on Orchestration of Apps Scripts – parallel threads and defeating quotas
I figured that if I implemented a rudimentary Map/Reduce capability that could split a meaty task into multiple chunks, run them all at the same time on separate threads, then bring the result together for final processing, then I could achieve these two goals. The TriggerBuilder service is key to this, but it’s rather difficult to control execution. Specifically this innocent looking sentence taken from the documentation.
Specifies the duration (in milliseconds) after the current time that the trigger will run. (plus or minus 15 minutes).
Plus or minus 15 minutes… (why specify in milliseconds?)
In any case, let’s press on and see what we have here. Here’s a primer for a way to orchestrate parallel tasks, or maybe you should take a look at Parallel process orchestration with HtmlService, which is another way of busting the 6 minute limit. Less complex and more reliable, but less geekworthy.
TriggerHappy
Libraries
I provide a library (cTriggerHappy) – MuIOvLUHIRpRlID7V_gEpMqi_d-phDA33, which you can include or fork as you prefer. Another library you need in you application is Database abstraction with google apps script, which is Mj61W-201_t_zC9fJg1IzYiz3TLx7pV4j. If you are forking the library, it needs Database abstraction with google apps script and Using named locks with Google Apps Scripts.
How to set up
This is fairly extreme scripting, so it’s a little complex. You should first take a look at the primer slides and start with a copy of an example application.
The control object.
This is used to manage orchestration, and specifies various things including some setup so you can use Database abstraction with google apps script. Although you could probably use any of the supported back end databases, I recommend Google Drive for the data, and a spreadsheet for logging and reporting. Here’s an example control function, which you should tailor to your own environment. There are 5 data types each of which could be held in independent data stores if required.
// this is the orchestration package for a piece of work that will be split into tasks
// it describes where to store itself, and keeps track of all the chunks
// it can be stored in any of the back end databases described in https://ramblings.mcpher.com/database-abstraction-and-google-apps-script
// this example is using google drive
// this identifies this scripts and the functions it will run
function getControl () {
return {
script: {
id: "1A7lJCKs1KFlj20fBqXjQFne0IhWV0ZpKcYrsYulwxvu__rSZBFnIJPwJ",
reduceFunction: 'workReduce',
taskFunction:'workMap',
processFunction:'workProcess'
},
taskAccess: {
siloId: 'tasks.json',
db: cDataHandler.dhConstants.DB.DRIVE,
driverSpecific: '/datahandler/driverdrive/tasks',
driverOb: null
},
logAccess: {
siloId: 'thappylog',
db: cDataHandler.dhConstants.DB.SHEET,
driverSpecific: '12pTwh5Wzg0W4ZnGBiUI3yZY8QFoNI8NNx_oCPynjGYY',
driverOb: null
},
reductionAccess: {
siloId: 'reductions.json',
db: cDataHandler.dhConstants.DB.DRIVE,
driverSpecific: '/datahandler/driverdrive/tasks',
driverOb: null
},
jobAccess: {
siloId: 'jobs.json',
db: cDataHandler.dhConstants.DB.DRIVE,
driverSpecific: '/datahandler/driverdrive/tasks',
driverOb: null
},
reportAccess: {
siloId: 'thappyreport',
db: cDataHandler.dhConstants.DB.SHEET,
driverSpecific: '12pTwh5Wzg0W4ZnGBiUI3yZY8QFoNI8NNx_oCPynjGYY',
driverOb: null
},
triggers: true,
delay:5000,
enableLogging:true,
threads:0,
stagger:1000
};
}
Other control parameters.
triggers:true
For testing, you should run with this false, then change to true when everything looks good.. This will cause no triggers to be generated, but will instead allow the process to be run sequentially in line
delay:5000
This is the number of milliseconds to wait between trigger creations and execution. The TriggerBuilder choreography seems to be a little more solid if you wait a bit before starting execution of a trigger
enableLogging:true
Debugging can be tricky with detached processes. This allows logging material to be written to the store described in logAccess:{}
threads:0
TriggerHappy will attempt to create as many parallel threads as are needed to run everything at once. This might cause some quota problems, so you can set this to some number other than 0. This limits the number of parallel processes to a specific number. When one completes, others will be generated as required.
stagger:1000
This is the number of milliseconds to wait between trigger creations. The TriggerBuilder choreography seems to be a little more solid if you wait a bit between creating triggers.
script.id:"1A7lJCKs1KFlj20fBqXjQFne0IhWV0ZpKcYrsYulwxvu__rSZBFnIJPwJ"
This is a unique script ID to allow multiple scripts to use the same database. Triggers associated with the given script ID will only execute on tasks it is meant to.
script.reduceFunction, taskFunction, processFunction
The names of the 3 functions that will be triggered to to the reduce, map and process functions.
Splitting up the work
Each job needs to be split into work packages called tasks. These tasks should be able to be run in any order and need to be independent of each other. Here’s an example, that is splitting a task into 5 chunks.
function splitJobIntoTasks () {
// need this for each function that might be triggered
var tHappy = new cTriggerHappy.TriggerHappy (getControl());
// i'm splitting the work in chunks
tHappy.log(null, 'starting to split','splitJobIntoTasks');
tHappy.init ();
var nChunks = 5;
for (var i=0; i < nChunks ; i++ ) {
// this is results package for each task chunk and where to store itself
// change this to the storage of your choice, and add any parameters you need to the parameters object
tHappy.saveTask ( {index:i, something:'some user values', numObs:tHappy.randBetween(20,100)});
}
// launch everything
tHappy.log(null, 'finished splitting');
tHappy.triggerTasks ();
tHappy.log(null, 'triggering is done','splitJobIntoTasks');
return nChunks;
}
The .saveTask() method allows you pass any parameters you want that will be available to your taskFunction. Note I’m using the .log() method regularly to report progress in the log.
the .triggerTasks() sets off the whole business of scheduling tasks to be mapped.
the taskFunction
This is the map stage. Tasks will be scheduled to run each of the chunks of work. The taskFunction is the one that gets called for each chunk. This is where you would execute the point of your application. In this example, I’m generating various random objects, controlled by values I passed to each chunk when I split the tasks in the first place. Depending on the setting of control.threads, all or some of these tasks will be triggered to run simultaneously. Additional threads will be initiated as required until there are no more tasks needing dealt with.
Note that there are a few mandatory requirements here.
-
- create an object with handleCode, handleError, and task properties. Fill the task property with something to do with the .somethingToMap() method.
var result = {data:null,handleCode:0,handleError:'',task:tHappy.somethingToMap()};
-
- store the result in an array, in the same object
result.data = obs;
-
- signal any errors if necessary
result.handleCode = TASK_STATUS.FAILED;
result.handleError = err;
tHappy.finished (result);
function workMap() {
// need this for each function that might be triggered
var tHappy = new cTriggerHappy.TriggerHappy (getControl());
// your result goes here
var result = {data:null,handleCode:0,handleError:'',task:tHappy.somethingToMap()};
// first find something to do
// if anything to do
if (result.task) {
tHappy.log( null, 'starting mapping for job ' + result.task.jobKey + '/' + result.task.taskIndex + ' task ' + result.task.key ,'workMap');
var ob = generateRandomObject(10);
var obs= [];
try {
// this is the work - for illustration use the params
for (var i=0;i < result.task.params.numObs;i++) {
obs.push(generateRandomValues(ob));
}
// store the result and status
result.data = obs;
}
catch(err) {
// store the error
result.handleCode = TASK_STATUS.FAILED;
result.handleError = err;
tHappy.log (null,err,'workMap');
throw(err);
}
// update task status
tHappy.finished (result);
tHappy.log(null, ' finished mapping');
}
return {handleError: result.handleError, handleCode: result.handleCode};
function generateRandomObject (n) {
var ob = {};
for (var i=0;i<n;i++){
ob['x'+i] = null;
}
return ob;
}
function generateRandomValues (ob) {
return Object.keys(ob).reduce(function(p,c) {
p = tHappy.arbitraryString(tHappy.randBetween(5,20));
return p;
},{});
}
}
the reduceFunction
This is the reduce stage. A reduce will automatically be scheduled if all the mapping tasks of the job are completed. It’s a fairly straightforward process, and your reduce function will almost certainly use the provided .reduce() method although you could do some special processing if you really wanted to. All that happens here is that all the independent results of the mapping tasks are combined into a single result.
although you could do some special things if you needed to.
function workReduce () {
// need this for each function that might be triggered
var tHappy = new cTriggerHappy.TriggerHappy (getControl());
// bring all the results together
tHappy.log(null, 'starting reduction','workReduce');
tHappy.reduce();
tHappy.log(null, 'finishing reduction','workReduce');
}
The processFunction
Once the reduce function has completed, you can now continue and finish the work. In our example, the random objects that we created in each of the chunks have been combined by taskReduce, and now the whole thing can be written to a sheet.
Note that there are a few mandatory requirements here.
-
- if there is anything to do, this will return the reduced data.
var reduced = tHappy.somethingToProcess ();
tHappy.processed(reduced);
-
- clean up all triggers when done – very important to avoid running out of trigger space
tHappy.cleanupAllTriggers();
function workProcess() {
// need this for each function that might be triggered
var tHappy = new cTriggerHappy.TriggerHappy (getControl());
// all is over, we get the reduced data and do something with it.
var reduced = tHappy.somethingToProcess ();
tHappy.log( null, 'starting processing for job ' + (reduced ? JSON.stringify(reduced) : ' - but nothing to do'),'workProcess');
if (reduced) {
// do something with the data - for this example we're going to copy it to a spreadsheet
var sheetHandler = new cDataHandler.DataHandler (
'thappytest',
cDataHandler.dhConstants.DB.SHEET,
undefined,
'12pTwh5Wzg0W4ZnGBiUI3yZY8QFoNI8NNx_oCPynjGYY');
if (!sheetHandler.isHappy()) {
throw ('failed to get handler for sheet processing');
}
// delete current sheet
tHappy.handledOk(sheetHandler.remove());
// add new data
tHappy.handledOk(sheetHandler.save(reduced.result));
// mark it as processed
tHappy.processed(reduced);
// we'll use the logger too
tHappy.log( null, 'finished processing','workProcess');
// clean up any triggers we know we're done
tHappy.cleanupAllTriggers();
}
}
Debugging
As mentioned, debugging is tricky. It’s better to have a function that runs your scripts on a subset of data serially as part of a script before moving on to running by triggers.
Set control.triggers = false, then create a function like the one below. This will run though the mapping of tasks one by one, then the reduce function, then the processing function. Once you have the result you want reliably you can move on to trying it in parallel by setting control.triggers = true;
function endTest () {
// divide up the work
var control = getControl();
var n = splitJobIntoTasks();
if (control.triggers) {
}
else {
// this is just a direct test end to end test, - no triggers
// do a couple of tasks
for (var i=0; i < n; i++) {
workMap();
}
// reduce
workReduce();
// do something with the result
workProcess();
}
}
Logging
a .log() method is provided to allow you to log whatever you want. Various logging is done by default, but you can add your own, for example
tHappy.log(null, 'finishing reduction','workReduce');
Here’s an example of a fragment of a log file – with triggering disabled
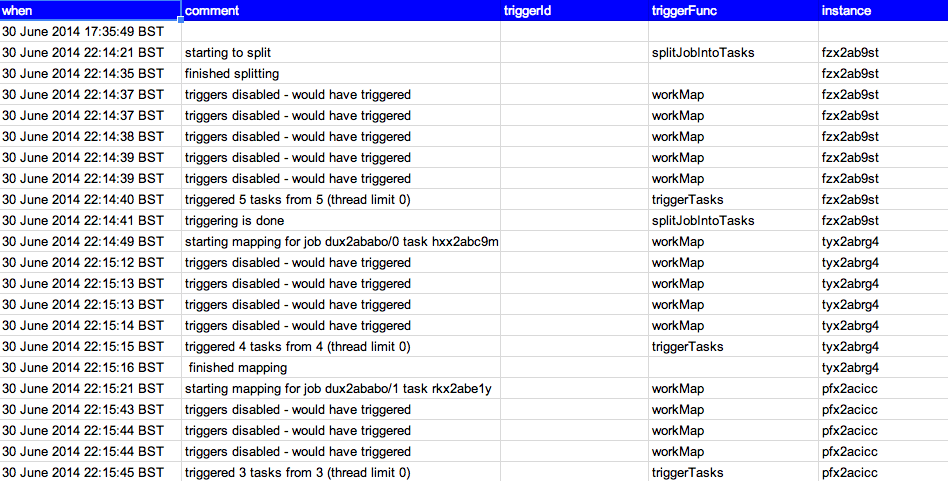
now the same thing with triggering enabled
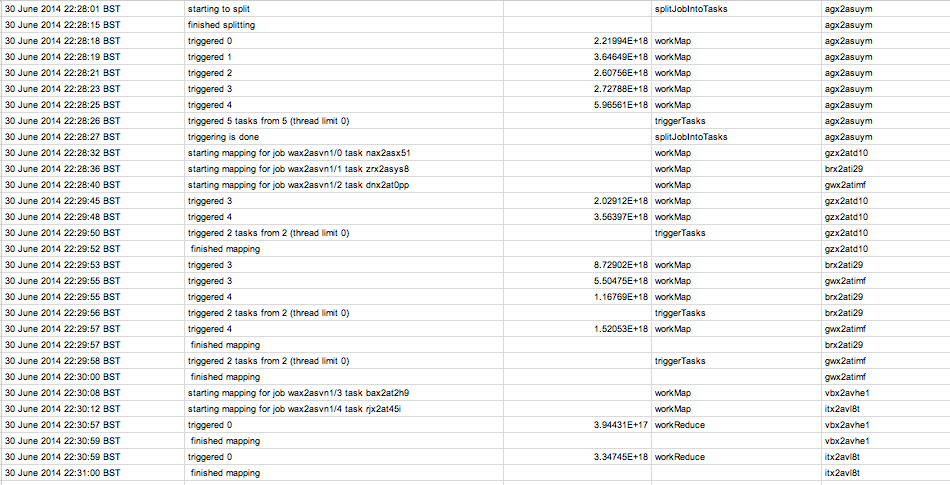
Reporting
It’s sometimes useful to take a look inside the orchestration files. If you’ve used Drive as your database, you can just open them. However, there is a .report() method to give a summary view like this.
function report () {
// need this for each function that might be triggered
new cTriggerHappy.TriggerHappy (getControl()).report();
}
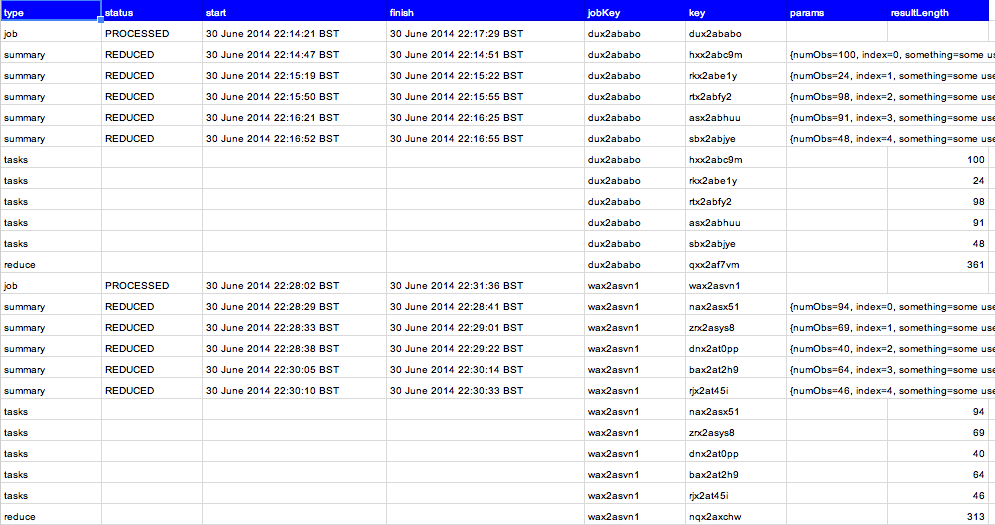
Keys and instances
Each task, job and reduction has a unique key. This will help you track down problems if you need to. You’ll also notice and instance id on the logger. Each triggered task also has a unique instance id so you can track its progress in the logger. Note that this is independent of the trigger ID, which is allocated by GAS. This instance id can be used on both triggered and inline operation.
Cleaning up
TriggerHappy does not automatically clean up its files. It may be that the reduce data, or even the individual task data needs to be reused. I’m also considering enabling a rescheduler so that entire jobs can be run multiple times – that would mean that the job files could also be useful. However, if you don’t need any of that, there are pre-baked methods for cleaning up. This function will clear everything.
function cleanupAll () {
// need this for each function that might be triggered
var tHappy = new cTriggerHappy.TriggerHappy (getControl());
tHappy.cleanupAllTriggers();
tHappy.cleanupTasks ();
tHappy.cleanupJobs();
tHappy.cleanupReduction();
tHappy.cleanupLog();
}
Summary
This approach is probably not for everyone, but it does exercise a number of interesting ideas such as Using named locks with Google Apps Scripts and triggers and of course the concept of using multiple threads – since it is the cloud after all. I have found that triggers are a little fragile, and that work executed in the context of a trigger executes more slowly that the same task as a regular script. For more like this see Google Apps Scripts snippets
Here’s a substantial example, copying from one database format to another – convertingfromscriptb
The Library Code
/**
* this object controls jobs and orchestration of tasks
*
* @param {Object} control describes how to access data for this session
* @return {TriggerHappy} self
*
* @constructor
*/
"use strict";
var TASK_STATUS = {
ACTIVE:1, // being currently mapped
FINISHED:2, // finished being processed
READY:3, // ready to process job + task
REDUCED:4, // status for an individual task/job - its been reduced
PROCESSED:5, // status for a job - its been processed
REDUCING:6, // status for a job - its reducing
PROCESSING:7, // status for a job - its processing
FAILED: -18 // this is the client error code reserved by DataHandler
};
function TriggerHappy (control) {
var self = this;
// -- local private variables
var reductionHandle_ ,
logHandle_,
taskHandle_,
jobHandle_,
job_,
control_ = control,
jobHandleKey_,
reportHandle_,
instance_;
//-- Utilities - also can be useful in the calling app
/**
* utilities - create a string of random characters
* @param {number} length
* @return {string} the random string
*/
self.arbitraryString = function (length) {
var s = '';
for (var i = 0; i < length; i++) {
s += String.fromCharCode(self.randBetween ( 97,122));
}
return s;
}
/**
* utilities - create a random integer between 2 points
* @param {number} min the minimum number
* @param {number} max the maximum number
* @return {number} the random number
*/
self.randBetween = function (min, max) {
return Math.floor(Math.random() * (max - min + 1)) + min;
};
/**
* utilities - generate a unique string
* @return {string} the unique string
*/
self.generateUniqueString = function () {
return self.arbitraryString(2) + new Date().getTime().toString(36);
};
// -- data handling, used DataHandler https://ramblings.mcpher.com/database-abstraction-and-google-apps-script/datahandler/
/**
* gets the handler associated with this store
* @param {Object} store the access store definition
* @return {DataHandler} the dbAbstraction hadnler
*/
self.getHandler = function (store) {
var handler = new cDataHandler.DataHandler (
store.siloId,
store.db,
undefined,
store.driverSpecific,
store.driverOb,
undefined,
true, // opt out of tracking
undefined,
undefined,
true); // disable all caching
if (!handler.isHappy()) {
throw ('failed to get handler for task'+JSON.stringify(store));
}
return handler;
};
/**
* checks that a DataHandler request succeeded or throws an error
* @param {Object} response a DataHandler response
* @param {boolean} strict whether to only allow an OK response
* @return {Object} the DataHandler reponse
*/
self.handledOk = function (response,strict) {
if (response.handleCode < 0 || (strict && response.handleCode !== cDataHandler.dhConstants.CODE.OK)) {
self.log(null,JSON.stringify(response), 'badly handled'+(strict && response.handleCode !== cDataHandler.dhConstants.CODE.OK)+response.handleCode < 0 );
throw JSON.stringify(response);
}
return response;
}
/**
* create and save a task definition
* @param {Object} params the task parameters to save
* @return {TriggerHappy} self
*/
self.saveTask = function (params) {
// get the latest job record
grabControl ("TriggerHappy.savetask", function (lock) {
self.refreshJob();
// record the task
job_.tasks.push({
key:self.generateUniqueString(),
params:params,
taskStatus:TASK_STATUS.READY,
taskIndex:job_.tasks.length,
jobKey:job_.key});
// update the job
self.handledOk(jobHandle_.update(jobHandleKey_, job_,lock));
});
return self;
};
/**
* get the latest job record
* @return {Object} a job
*/
self.refreshJob = function (optKey) {
var key = optKey || job_.key;
var d = self.refresh ( jobHandle_, key);
job_ = d.data[0];
jobHandleKey_ = d.handleKeys[0];
return job_;
};
/**
* get a record
* @param {DataHandler} handle a DataHandler object
* @param {string} key the key
* @return {Object} a task/job record
*/
self.refresh = function (handle, key) {
var d = self.handledOk ( handle.query({key:key},undefined,1,true));
if (d.data.length !==1) {
throw (key + ' should have 1 record not ' + d.data.length);
}
return d;
};
// set up the handlers for the different types of data stored
logHandle_ = self.getHandler ( control_.logAccess);
taskHandle_ = self.getHandler ( control_.taskAccess);
reductionHandle_ = self.getHandler ( control_.reductionAccess);
jobHandle_ = self.getHandler ( control_.jobAccess);
reportHandle_ = self.getHandler ( control_.reportAccess);
instance_ = self.generateUniqueString();
/**
* create and save job record
* @param {Object} params any parameters you want to save with this job
* @return {TriggerHappy} self
**/
self.init = function (params) {
// create a new job
grabControl ("TriggerHappy.init", function (lock) {
job_ = self.createJob();
var data = self.handledOk(jobHandle_.save(job_));
});
return self;
};
/**
* sets a task status to ACTIVE
* @param {Object} result containingthe task to be updated
* @return {TriggerHappy} self
*/
self.workingOn = function (task) {
// should already be protected when called
self.refreshJob(task.jobKey);
try {
job_.tasks[task.taskIndex].taskStatus = TASK_STATUS.ACTIVE;
job_.tasks[task.taskIndex].start = Date.now();
// update the job
self.handledOk(jobHandle_.update(jobHandleKey_, job_));
}
catch (e) {
var m = 'failed to claim job ' +e + ' job ' + JSON.stringify(job_);
self.log (null, m,'workingOn');
throw m;
}
return self;
};
function grabControl(who, f) {
if (control_.debugGrabbing) {
self.log(null,who,'trying to grab ' + new Date().getTime());
}
var info;
var r = new cNamedLock.NamedLock().setKey('thappy' , control_.jobAccess).protect(who+'_'+instance_, function (lock) {
if (control_.debugGrabbing) {
info = ':lock-' + JSON.stringify(lock.getInfo());
self.log(null,who,'grabbed ' + new Date().getTime() + info);
}
return f();
}).result;
if (control_.debugGrabbing) {
self.log(null,who,'ungrabbed ' + new Date().getTime() + info);
}
return r;
}
/**
* sets a task status to FINISHED and fires off a reduce trigger. if all tasks for this job are finished, sets job status to finished
* @param {Object} result the result containing the task to be updated
* @return {TriggerHappy} self
*/
self.finished = function (result) {
grabControl ("TriggerHappy.finished", function (lock) {
// refresh the job
self.refreshJob(result.task.jobKey);
if (job_.tasks[result.task.taskIndex].key !== result.task.key) {
lock.unlock();
var m = 'expected ' + job_.tasks[result.task.taskIndex].key + ' but got ' + result.task.key;
self.log(null,m,'finished with error');
throw m;
}
job_.tasks[result.task.taskIndex].finish = new Date().getTime();
job_.tasks[result.task.taskIndex].taskStatus = TASK_STATUS.FINISHED;
// and a job record
job_.taskStatus = job_.tasks.every (function(d) { return d.taskStatus === TASK_STATUS.FINISHED; }) ? TASK_STATUS.FINISHED : job_.taskStatus;
if (job_.taskStatus === TASK_STATUS.FINISHED) {
job_.finished = new Date().getTime();
}
self.handledOk ( jobHandle_.update ( jobHandleKey_, job_));
// now we create & save a task record
self.handledOk ( taskHandle_.remove( { key:result.task.key}) );
self.handledOk ( taskHandle_.save ( {
key:result.task.key,
jobKey:job_.key,
result:result.data
}) );
});
// let someone else in if they are waiting, then do any reduction triggers
grabControl ("TriggerHappy.finished.trigger.reduce", function (lock) {
// we can provoke some reductions if there are any
var nTriggered = 0;
self.getJobsToReduce().data.forEach (function(job,i,a) {
if (!control_.threads || nTriggered < control_.threads) {
self.triggerAThing (job.reduceFunction,i);
// apparently have more success of everything running if we stagger the submission a bit too
if(control_.stagger && i+1 < a.length) {
Utilities.sleep(control_.stagger);
}
nTriggered++;
}
});
if (nTriggered && control_.killStage) {
// in this mode, we delete all triggers for the previous stage(s) when this one is completed
cleanupFuncTrigger(control_.script.taskFunction);
}
});
// provoke another task to sweep up case of thread limit.
self.triggerTasks(1);
return self;
};
/**
* find jobs that are ready to be reduced, get the task data, and created a reduced file
* ready to be reduced : job.taskStatus = FINISHED
* when completed : job.taskStatus = REDUCED
* when under way : job.taskStatus = REDUCING
*/
self.reduce = function () {
// get any jobs needing reducing
var jobs;
// grab any josb for reduction
grabControl ( 'reduce' , function () {
jobs = self.getJobsToReduce().data;
jobs.forEach ( function (job,i) {
self.updateJobStatus(job.key,TASK_STATUS.REDUCING);
});
});
// get the associated tasks
jobs.forEach ( function (job,i) {
self.refreshJob (job.key);
// get tasks needing reduced
var tasks = self.handledOk( taskHandle_.query({jobKey:job_.key}, undefined, 1, true));
var result = [];
// do it in the order of the job
// dont need to protect this since we already have the job keys to work on and have reserved them
// TODO add an instance reserved by field for double checking
job_.tasks.forEach( function (t) {
var task = tasks.data.filter (function (d) { return d.key === t.key});
if (task.length !== 1) {
var m = 'couldnt find finished task ' + t.key + ' for job ' + job_.key;
self.log(null,m , 'reduce');
throw m;
}
Array.prototype.push.apply (result, task[0].result);
t.taskStatus = TASK_STATUS.REDUCED;
});
// this does the actual work
var reduction = self.createReduction();
reduction.result = result;
reduction.finish = new Date().getTime();
// need to grab control to update the job record
grabControl ('reduce', function () {
// in case theres a failed attempt previously
self.handledOk (reductionHandle_.remove({jobKey:job_.key}));
self.handledOk (reductionHandle_.save (reduction));
job_.taskStatus = TASK_STATUS.REDUCED;
job_.reduction = reduction.key;
job_.finish = new Date().getTime();
self.handledOk( jobHandle_.update (jobHandleKey_, job_), true);
});
});
// we can provoke some processing if there are any
grabControl ('reduce', function() {
var nTriggered = 0;
self.getJobsToProcess().forEach (function(job,i) {
if (!control_.threads || nTriggered < control_.threads) {
nTriggered++;
self.triggerAThing (job.processFunction,i);
}
});
if (nTriggered && control_.killStage) {
// in this mode, we delete all triggers for the previous stage(s) when this one is completed
cleanupFuncTrigger(control_.script.taskFunction);
cleanupFuncTrigger(control_.script.reduceFunction);
}
});
return self;
}
/**
* creates a reduction
* @param {Object} params any params object you need to associate with this this task instance
* @return {Object} the created task
*/
self.createReduction = function (params) {
// one of these per task
var key = self.generateUniqueString();
return {
key: key,
jobKey:job_.key,
result:null,
start: new Date().getTime(),
finish: null,
handleCode:0,
handleError:'',
params:params
};
};
/**
* creates a job
* @param {Object} params any params object you need to associate with this this job instance
* @return {Object} the created job
*/
self.createJob = function (params) {
// one of these per task
var key = self.generateUniqueString();
return {
key:self.generateUniqueString(),
id: control_.script.id,
reduceFunction: control_.script.reduceFunction,
taskFunction: control_.script.taskFunction,
processFunction: control_.script.processFunction,
tasks:[],
reduction:null,
start: new Date().getTime(),
finish: null,
handleCode:0,
handleError:'',
params:params,
taskStatus:TASK_STATUS.READY
};
};
/**
* gets a single task that needs to be done
* @return {Object} one item from the dataHandler response for data for tasks that are redy to go for this script/workfunction
*/
self.somethingToMap = function () {
var task;
grabControl ('somethingtomap', function() {
var stuffToDo = self.getStuffToDo();
if ( stuffToDo.length > 0 ) {
// claim it
task = stuffToDo[0];
self.workingOn(task);
}
});
return task;
};
/**
* gets a single task that needs to be processed
* @param {boolean} optRedoFailure items in processing status (redo failures)
* @param {boolean} optRedo items in precessed status (redo)
* @return {Object} one item from the dataHandler response for data for reduction that is ready to go
*/
self.somethingToProcess = function (optRedoFailure,optRedo) {
var reduced, states = [TASK_STATUS.REDUCED];
grabControl ('somethingToProcess', function() {
if (optRedoFailure) {
states.push(TASK_STATUS.PROCESSING);
}
if (optRedo) {
states.push(TASK_STATUS.PROCESSED);
}
var stuffToDo = self.getJobsToProcess(states);
if ( stuffToDo.length > 0 ) {
// claim it
var job = stuffToDo[0];
self.refreshJob (job.key);
reduced = self.refresh (reductionHandle_, job.reduction).data[0];
self.processing(reduced);
}
});
return reduced;
};
/**
* gets all the jobs that are ready for mapping
* @param {Array.number} optStates the job states to allow
* @return {Array.Object} an array of task objects that need to be worked on
*/
self.getJobsToProcess = function (optStates) {
var states = optStates || [TASK_STATUS.REDUCED], jobs=[];
states.forEach (function (d) {
var ob = {id:control_.script.id,processFunction:control_.script.processFunction, taskStatus:d };
var result = self.handledOk(jobHandle_.query (ob,undefined,1));
Array.prototype.push.apply (jobs, result.data);
});
return jobs;
};
/**
* marks the reduced job as being processed
* @return {TriggerHappy} self
*/
self.processing = function (reduced) {
return self.updateJobStatus(reduced.jobKey,TASK_STATUS.PROCESSING);
};
/**
* marks the reduced job as been processed
* @return {TriggerHappy} self
*/
self.processed = function (reduced) {
return grabControl ('processed' , function () {
self.updateJobStatus(reduced.jobKey,TASK_STATUS.PROCESSED);
});
};
/**
* refresh job and update its status
* @param {string} key the job key
* @param {number} status the status
* @return {TriggerHappy} self
*/
self.updateJobStatus = function (key,status) {
self.refreshJob(key);
job_.taskStatus = status;
self.handledOk(jobHandle_.update(jobHandleKey_, job_));
return self;
}
/**
* gets the jobs that are ready for reduction
* @return {Array.Object} an array of jobs that are ready for reduction
*/
self.getJobsToReduce = function () {
var ob = {id:control_.script.id,reduceFunction:control_.script.reduceFunction,taskStatus:TASK_STATUS.FINISHED};
return self.handledOk(jobHandle_.query (ob),undefined,1);
};
/**
* gets the tasks associated with this job and changes from active to ready - dont use except for patching
* @return {Object} the dataHandler response for data for tasks that are redy to go for this script/workfunction
*/
self.patchReady = function () {
grabControl ('makeReady', function() {
// find any jobs that are waiting for tasks to finish
var jobs = self.handledOk(jobHandle_.query ({id:control_.script.id, taskFunction:control_.script.taskFunction, taskStatus:TASK_STATUS.READY}),undefined,1);
var tasks = [];
// get the associated tasks
jobs.data.forEach ( function (job) {
job.tasks.map = function(d) {
if (d.taskStatus === TASK_STATUS.ACTIVE) {
d.taskStatus === TASK_STATUS.READY;
}
return d;
};
self.handledOk(jobHandle_.update(jobHandleKey_, job));
});
});
}
/**
* gets the tasks associated with this job neding doing
* @param {number} the taskStatus we are looking for
* @return {Object} the dataHandler response for data for tasks that are redy to go for this script/workfunction
*/
self.getStuffToDo = function () {
// find any jobs that are waiting for tasks to finish
var jobs = self.handledOk(jobHandle_.query ({id:control_.script.id, taskFunction:control_.script.taskFunction, taskStatus:TASK_STATUS.READY}),undefined,1);
var tasks = [];
// get the associated tasks
jobs.data.forEach ( function (job) {
Array.prototype.push.apply (tasks, job.tasks.filter (function(d) { return d.taskStatus === TASK_STATUS.READY; }));
});
return tasks;
};
/**
* makes a log entry about trigger
* @param {Trigger|null} trigger the trigger to log
* @param {string} commentary some comment to log
* @param {string} func name in case there is no trigger
*/
self.log = function (trigger,commentary,func) {
if (control_.enableLogging) {
return logHandle_.save ( {
when: new Date().toLocaleString(),
comment: commentary || '',
triggerId: trigger? trigger.getUniqueId() : '',
triggerFunc: trigger ? trigger.getHandlerFunction() : (func ? func : ''),
instance:instance_,
id: control_.script.id
});
}
};
/**
* clean up all known tasks for this scriptid and work function
* @return {TriggerHappy} self
*/
self.cleanupTasks = function () {
cleanup (taskHandle_);
return self;
};
/**
* clean up all known tasks for this scriptid and work function
* @return {TriggerHappy} self
*/
self.cleanupJobs = function () {
cleanup (jobHandle_);
return self;
};
/**
* clean up all known tasks for this scriptid and work function
* @return {TriggerHappy} self
*/
self.cleanupReduction = function () {
cleanup (reductionHandle_);
return self;
};
/**
* clean up all known tasks for this scriptid and work function
* @return {TriggerHappy} self
*/
self.cleanupLog = function () {
self.handledOk(logHandle_.remove ({id:control_.script.id},undefined,1));
return self;
};
/**
* clean up all known triggers
* @return {TriggerHappy} self
*/
self.cleanupAllTriggers = function () {
possibleFunctions().forEach(function(t) {
cleanupFuncTrigger(t);
});
return self;
function possibleFunctions() {
return [control_.script.taskFunction,control_.script.reduceFunction,control_.script.processFunction];
}
};
/**
* create enough triggers to process each task in paralell
* @param {number} optLimit this optionally limits the number- control_.threads overrides this.
* @return {TriggerHappy} self
*/
self.triggerTasks = function (optLimit) {
grabControl ('triggerTasks', function() {
// find any jobs associated with this script and this taskFunction and that are ready to go
var jobs = self.handledOk(
jobHandle_.query ({
id:control_.script.id,
taskFunction:control_.script.taskFunction
},
{sort:'start'},
1,
true
));
// get the associated tasks
var nTriggered = 0,nPot = 0;
var nMax = control_.threads ? control_.threads : (optLimit ? optLimit : 0 ) ;
jobs.data.forEach ( function (job,i) {
job_ = job;
jobHandleKey_ = jobs.handleKeys[i];
// trigger a task for each outstanding thing
job_.tasks.forEach ( function (d,i) {
if (d.taskStatus === TASK_STATUS.READY) {
if (!nMax ||nMax > nTriggered) {
self.triggerAThing (job_.taskFunction,i);
nTriggered++;
}
nPot++;
}
});
});
if (nTriggered) {
self.log (null, 'triggered ' + nTriggered + ' tasks from ' + nPot + ' (thread limit ' + control_.threads + ')' ,'triggerTasks');
}
});
return self;
};
/**
* trigger some work
* @param {string} func the function to be triggered
* @return {TriggerHappy} self
*/
self.triggerAThing = function (func,nSeq) {
if (control_.triggers) {
var trigger = triggerItem (func, self.tweakDelay(nSeq));
if (trigger) {
self.log(trigger,'triggered '+ nSeq , func);
}
else {
// give up and try again later
self.log(null, "failed to launch " + nSeq, func);
throw ('failed to trigger');
}
}
else {
self.log (null, 'triggers disabled - would have triggered', func);
}
return self;
};
self.tweakDelay = function (nSeq) {
nSeq = nSeq || 0;
var delay = control_.delay || 2000;
return delay + self.randBetween(0,Math.floor(delay/2)) + delay * nSeq/10;
};
self.getStatusText = function (code) {
var k = Object.keys(TASK_STATUS).filter (function(c) {
return TASK_STATUS === code;
});
return k.length ? k[0] : 'CODE NOT FOUND:' + code;
};
self.report = function () {
var report = [];
self.handledOk ( jobHandle_.query ({id:control_.script.id},undefined,1)).data.forEach(function(d) {
report.push( {
type:'job',
status:self.getStatusText(d.taskStatus),
start:new Date(d.start).toLocaleString(),
finish:new Date(d.finish).toLocaleString(),
jobKey:d.key,
key:d.key
});
report.push.apply (report, d.tasks.map( function(t) {
return {
type:'summary',
status:self.getStatusText(t.taskStatus),
start:new Date(t.start).toLocaleString(),
finish:new Date(t.finish).toLocaleString(),
jobKey:t.jobKey,
key:t.key,
params:t.params };
}));
report.push.apply (report, taskHandle_.query({jobKey:d.key},undefined, 1).data.map(function(t) {
return {
type:'tasks',
status:t.taskStatus,
resultLength:t.result.length,
jobKey:t.jobKey,
key:t.key };
}));
report.push.apply (report, reductionHandle_.query({jobKey:d.key},undefined, 1).data.map(function(t) {
return {
type:'reduce',
status:t.taskStatus,
resultLength:t.result.length,
jobKey:t.jobKey,
key:t.key };
}));
});
self.handledOk(reportHandle_.remove());
self.handledOk(reportHandle_.save(report));
};
function cleanupFuncTrigger (func) {
try {
var triggers = ScriptApp.getProjectTriggers();
for (var i = 0; i < triggers.length; i++) {
var t = triggers[i].getHandlerFunction();
if (t === func) {
ScriptApp.deleteTrigger(triggers[i]);
}
}
}
catch(err) {
// not the end of the world if it fails (as it sometimes does with server error)
}
};
/**
* trigger an item
* @param {string} work name of function
* @param {number} delay how many ms from now to start it
* @return {Trigger} for chaining
*/
function triggerItem (work,delay,pass) {
pass = pass || 0;
try {
return ScriptApp.newTrigger(work)
.timeBased()
.at(new Date(new Date().getTime() + delay))
.create();
}
catch (err) {
// try a couple of times in case its one of those inexplicable server error things
if (pass < 2) {
Utilities.sleep (200 + Math.random() * 1000);
return triggerItem (work,delay,++pass);
}
else {
throw(err);
}
}
}
function cleanup (handle) {
var d = handle.remove ();
if (d.handleCode < 0) throw( JSON.stringify(d));
}
return self;
};
For more like this see Google Apps Scripts Snippets
For help and more information join our forum, follow the blog, follow me on Twitter